Capítulo 4. Arquivos e Diretórios
Em um sistema Linux, temos uma estrutura de diretórios diferente de outros sistemas operacionais. Os arquivos ali dispostos, a princípio, parecem estar jogados aleatoriamente nos diversos diretórios existentes. Mas, felizmente, há uma certa ordem e uma lógica, fazendo com que cada diretório do sistema tenha uma finalidade específica.
O principal objetivo deste capítulo é mostrar que os arquivos e diretórios em um sistema Linux estão organizados de forma que cada um tem uma função específica e o conjunto torna o sistema confiável, integrado e seguro.
Sistema de Arquivos
Sistema de arquivos é a forma que o sistema operacional usa para representar determinada informação em um espaço de armazenagem. É o método de identificar e indexar as informações que estão armazenadas em qualquer mídia: disquetes, discos rígidos, drives em memória, CDs, etc.
Quando se prepara um disco para o trabalho através do processo de formatação física, criam-se os meios magnéticos necessários para armazenar os dados. Este processo faz uma preparação do dispositivo de armazenagem para que ele possa receber um sistema de arquivos e futuramente os dados do usuário. Um sistema de arquivos, portanto, é necessário para manter padrões, para controlar o tamanho das partições, permissões de arquivos, tamanho dos arquivos e sua organização, entre muitas outras funções.
Será visto primeiramente quais os principais tipos de sistemas de arquivos que existem e que são criados em um processo de formatação:
-
ext: sistema de arquivos estendido (extended filesystem). É o sistema de arquivos mais utilizado no Linux. Ele fornece padrões para arquivos regulares, diretórios, arquivos de dispositivos e links simbólicos, entre outras características avançadas. Desenvolvedores trabalham para ampliar a capacidade deste sistema de arquivos para o suporte a controle de acesso conforme o padrão POSIX e compressão de arquivos on the fly (o arquivo é descompactado no momento em que é acessado).
Suas principais ramificações são os sistemas ext2 e ext3.
-
vfat: este é o sistema de arquivos (volume FAT) dos sistemas Windows®9x e Windows NT®.
-
nfs: sistema de arquivos de rede, utilizado para acessar diretórios de máquinas remotas, que permite o compartilhamento de dados na rede.
-
reiserfs: sistema de arquivos com suporte a características mais avançadas, como por exemplo melhor performance para diretórios muito grandes e suporte a transações (journalling).
-
iso9660: sistema de arquivos do CD-ROM.
-
hpfs: sistema de arquivos do OS/2®.
Existem muitos outros tipos de sistemas de arquivos, dependendo da sua aplicação e de que sistema você precisará. Examine as páginas de manual do fstab e do mount para mais detalhes sobre os vários tipos de sistema de arquivos.
Juntamente com o conceito de sistema de arquivos existe o conceito de partição. Particionar um dispositivo é dividi-lo de forma que cada uma das suas partes, denominadas partições, possam receber um tipo de sistema de arquivo e estejam preparadas para receber as informações.
Sistema de arquivos e partições são normalmente confundidos, quando na verdade são conceitos totalmente diferentes. As partições são áreas de armazenamento, criadas durante o processo de particionamento, sendo que cada partição funciona como se fosse um disco rígido (ou dispositivo utilizado). Para se utilizar uma partição, entretanto, deve-se criar um sistema de arquivos, ou seja, um sistema que organize e controle os arquivos e diretórios desta partição. Uma partição só pode ter apenas um sistema de arquivo.
Apesar da diferença, muitas vezes os termos são utilizados de modo similar. Não é uma linguagem totalmente errada, pois é muito utilizada diariamente, mas deve-se ter em mente a diferença entre os termos.
O sistema de arquivos mais importante em um sistema Linux é o sistema de arquivos raiz. Ele geralmente está montado no diretório "/", também chamado de diretório raiz. Um sistema de arquivos raiz deve conter o necessário para suportar um sistema Linux completo, e para tanto deve incluir alguns requisitos básicos:
-
A estrutura básica do sistema de arquivos, geralmente agrupando os diretórios em árvores e obedecendo a alguns padrões.
-
Conjunto mínimo de diretórios: /dev, /proc e /bin, entre outros.
-
Conjunto básico de utilitários e comandos: ls, cp, mv.
-
Conjunto mínimo de arquivos de configuração: rc, inittab, fstab.
-
Arquivos de dispositivo: /dev/hd*, /dev/tty*, /dev/fd0.
-
Bibliotecas que disponibilizem as funções básicas necessárias aos utilitários.
A estrutura dos sistemas de arquivos do Linux prevê um agrupamento que permite maior organização de dados, o que aumenta a funcionalidade do sistema. Os comandos estão todos em uma determinada área, todos os arquivos de dados em uma outra, documentação em uma terceira, e assim por diante. Além disso, o diretório raiz geralmente não contém nenhum arquivo, exceto, em algumas distribuições, pela imagem de inicialização do sistema. Todos os outros arquivos estão em subdiretórios do raiz.
Após esta primeira apresentação, passamos agora a mostrar como é formado o diretório raiz de um sistema Linux. Veja a estrutura básica de diretórios abaixo:
/bin |
-
O diretório raiz, representado pela "/", é específico de cada máquina. Pode ficar tanto em um disco físico quanto na memória da máquina ou em uma unidade de rede. É o diretório principal, que contém todos os arquivos e diretórios do sistema.
-
O diretório /bin é o diretório que contém o mínimo necessário para a inicialização do sistema. Serão necessárias ferramentas que se encontram em outros diretórios para que a máquina fique operacional. A maioria dos programas possui o seu arquivo executável neste diretório.
-
/dev é o local onde ficam armazenadas as referências aos dispositivos presentes na máquina, para o controle destes dispositivos. Esse diretório contém apontadores para, por exemplo, o drive de disquetes, os discos da máquina, terminais virtuais, portas de acesso seriais e paralelas, etc. Os controladores são automaticamente criados durante a instalação do sistema e posteriormente podem ser criados através do comando MAKEDEV.
-
O diretório /home contém os diretórios pessoais dos usuários e suas configurações.
-
O diretório /proc fornece informações sobre o kernel e sobre os processos que estão rodando no momento, além de informações sobre a utilização de alguns dispositivos. Alguns parâmetros do kernel podem ser alterados diretamente nesses arquivos, fazendo com que as modificações passem a valer imediatamente. Esse diretório não ocupa espaço nenhum em disco e as informações ali presentes são geradas apenas quando solicitadas.
-
O diretório /usr contém comandos, bibliotecas, programas, páginas de manual e outros arquivos que não mudam mas que se fazem necessários para a operação normal do sistema. Como são estáticos, é interessante compartilhar esses arquivos pela rede, o que resulta numa grande economia de espaço em disco utilizado.
-
O diretório /boot contém informações para o gerenciador de inicialização do sistema. É aqui que normalmente ficam as informações para o carregador do sistema operacional e também a imagem para a pré-carga do sistema (initrd).
-
/etc é um dos mais importantes diretórios da máquina. Nele ficam a maioria dos arquivos de configuração e manipulação dos serviços essenciais ao sistema, a maioria dos arquivos de configuração de acesso a rede e de comunicação, arquivos de configuração do Sistema de Janelas X[1], arquivos de configuração do idioma do sistema, de atualizações, enfim, de muitas funcionalidades da máquina.
-
/lib é o diretório onde ficam as bibliotecas básicas do sistema. Elas são compartilhadas por diversos programas, principalmente os que se encontram no diretório raiz.
-
O diretório /var contém arquivos que possuem dados variáveis. Neste diretório estão arquivos e diretórios de spool, arquivos de log, arquivos de configuração de correio eletrônico e de news, entre outros. O diretório /var também guarda arquivos que precisam de uma freqüente atualização, como os arquivos de conteúdo do servidor Apache ou do servidor de FTP.
-
/sbin contém ferramentas de uso do superusuário e que geralmente são usadas por serviços básicos da máquina. Ficam nesse diretório programas como os responsáveis pela carga de módulos do kernel, ativação e interrupção das interfaces de rede, manutenção dos sistemas de arquivos e de outras atividades.
Existem, além destes, alguns diretórios que também são importantes para a complementação da funcionalidade do sistema, e estão presentes em praticamente todos os sistemas Linux, apesar de não serem estritamente obrigatórios. São eles:
-
O diretório /mnt é o diretório utilizado para o acesso a dispositivos de mídia, como disquetes e CD-ROM. Ele é utilizado como ponto de montagem para a maioria destes dispositivos.
-
O diretório /tmp serve como repositório para arquivos temporários, sendo utilizado para programas que são executados após a ativação do sistema, ou seja, este diretório serve como espaço extra para vários programas e aplicações.
-
Alguns programas são projetados para serem instalados sob o diretório /opt. Ele pode ser útil por questões de espaço.
Apesar das diferentes partes acima serem chamadas de diretórios, não há obrigatoriedade que elas estejam separadas. Elas podem estar facilmente no mesmo sistema de arquivos em uma pequena máquina utilizada por um único usuário que deseje mantê-las de uma forma mais simplificada.
Alguns destes diretórios podem ser montados em suas próprias partições. Suponha que, por questões de espaço ou segurança, é desejável que o diretório dos usuários esteja em uma outra partição. Então, é criada uma outra partição que será montada no diretório /home e que terá, por exemplo, o mesmo sistema de arquivos utilizado pelo sistema de arquivos raiz. Essa separação em um sistema de arquivos à parte é interessante pois facilita determinadas tarefas administrativas, como gerenciamento da quantidade de espaço que cada usuário pode utilizar e a manutenção de cópias de segurança[2].
Portanto, a árvore de diretórios pode estar dividida ainda em diferentes sistemas de arquivos, dependendo do tamanho de cada disco e de quanto espaço será alocado para cada finalidade.
Sistema de Arquivos ext3
O Conectiva Linux pode ser instalado sobre um sistema de arquivos ext3. Esse sistema é semelhante ao ext2, porém utiliza o sistema de journalling de dados. O journalling divide a fase de escrita dos dados em duas partes: Agendamento e Escrita. Essa estrutura permite que, em caso de desligamento acidental do sistema, não seja necessário executar um fsck no disco (o que pode demorar muito tempo dependendo do tamanho do seu sistema de arquivos).
Caso ocorra uma interrupção inesperada do sistema, como por exemplo uma queda de luz durante a fase de "agendamento", o arquivo não é atualizado, continuando intacto. Caso esse problema ocorra durante a fase de escrita, o sistema possui a agenda (journal) na qual estão os dados necessários para fazer as alterações no arquivo.
O fato do sistema escrever várias vezes a mesma alteração em arquivos, não torna a operação lenta, pois ele também otimiza o movimento das cabeças do disco rígido.
O usuário que já possui o Conectiva Linux e o sistema de arquivos ext2 instalado pode facilmente convertê-lo para o ext3. Para fazê-lo, proceda da seguinte maneira:
Converta o sistema de arquivos de ext2 para ext3 utilizando o comando tune2fs:
# tune2fs -j /dev/hdxx |
Deve-se também alterar o sistema de arquivos no arquivo /etc/fstab. Para isso, altere a linha:
/dev/hdxx / ext2 defaults 0 0 |
para
/dev/hdxx / ext3 defaults 1 1 |
Depois de ter alterado o arquivo /etc/fstab, execute o comando mkinitrd como mostrado abaixo:
# mkinitrd /boot/initrd-versao_do_kernel.img versao_do_kernel |
O arquivo de configuração do gerenciador de inicialização deve ser alterado para que utilize o initrd criado. No caso do grub, o arquivo de configuração fica em /boot/grub/menu.lst. Abaixo da linha que indica o kernel a ser utilizado durante a inicialização, acrescente a seguinte linha:
initrd = (hdx,x)/boot/initrd-versao_do_kernel.img |
Deixe, por enquanto, a entrada com o sistema ext2 intacta, para que no caso de ocorrer algum problema, você poderá retornar e fazer os reparos necessários.
Depois de ter realizado todos os passos descritos acima, reinicie a máquina para que o sistema reconheça o ext3.
Trabalhando com Sistema de Arquivos
Durante o processo de instalação de um sistema Linux um sistema de arquivos é escolhido para cada partição especificada. Se for necessária alguma mudança ou atualização, será possível executá-la pelo menu Configuração -> Sistema de arquivos -> Acessar dispositivos locais do Linuxconf. Veja a Figura 4-1, que mostra como configurar um sistema de arquivos para partições locais, ou seja, da máquina.
Clicando sobre os pontos de montagem é possível editá-los. Você pode observar onde a partição está localizada, qual seu tipo e o seu ponto de montagem na aba Base. Deve-se tomar muito cuidado ao fazer modificações, pois elas poderão modificar totalmente o sistema. A aba Opções também traz informações importantes como, por exemplo, se a partição pode ser montável por usuários, se possui suporte a dispositivos especiais e se o dono do dispositivo pode montá-la.
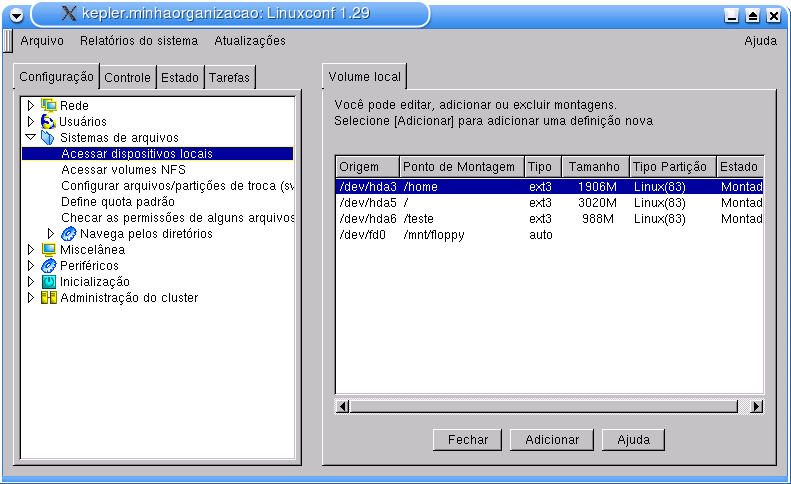
Para configurar sistemas de arquivos de rede, como por exemplo nfs, dirija-se ao menu Configuração->Sistema de arquivos->Acessar volumes NFS; o procedimento a ser seguido é o mesmo utilizado para dispositivos locais, bastando ter as informações sobre a rede e os pontos de montagem.
Sistema de Quotas
Um sistema de arquivos também pode trabalhar com quotas. Um sistema de quotas define limites de uso do disco para usuários e seus programas. Os usuários são forçados a permanecer sob seu limite de consumo de disco, tirando deles a habilidade de consumir de forma ilimitada o espaço em disco do sistema. A quota é gerenciada seguindo uma base por usuário e por sistema de arquivo. Se existe mais de um sistema de arquivo onde um usuário pode criar arquivo, então a quota tem de ser estabelecida para cada sistema de arquivo separadamente.
É possível configurar o sistema de quotas através do Linuxconf pelo menu Configuração ->Sistema de arquivos->Acessar dispositivos locais. Selecione o dispositivo no qual se deseja aplicar o sistema de quotas (por exemplo, o dispositivo do disco rígido ou /dev/hda*) e na tela de edição habilite a opção Opções->Ativar quota por usuário. Ativado o sistema de quota, basta apenas configurá-lo em Configuração->Sistema de arquivos->Define quota padrão. Observe a Figura 4-2 que exibe esta tela.
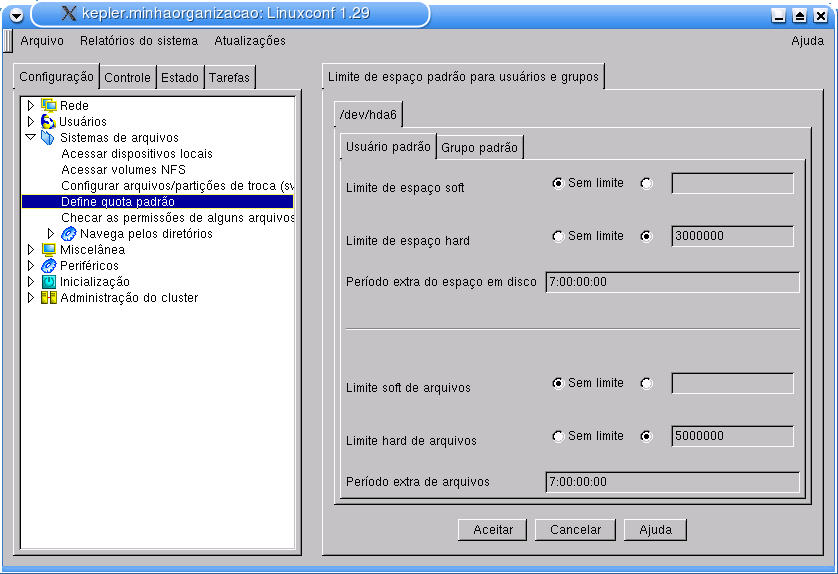
Os limites de espaço para software, hardware e para arquivos devem ser preenchidos em bytes. Após a finalização da configuração, o Linuxconf pede algumas confirmações durante a sua finalização. Basta confirmar e finalizar o Linuxconf. A configuração de quotas para grupos está na mesma tela (aba Grupo Padrão) e segue o mesmo padrão.
Nota: As opções do tipo Período Extra na configuração da quota são interessantes, pois permitem a configuração de um período para que o usuário possa fazer modificações (remover arquivos, por exemplo), antes que sua área fique inacessível.
Diretórios e Arquivos Importantes
Cada diretório apresenta uma estrutura particular e alguns arquivos-chave para a configuração do sistema. Devemos lembrar aqui que um dispositivo físico é tratado no Linux como um arquivo e se encontra no diretório /dev. No início de cada arquivo, geralmente encontra-se um comentário, explicando a que se destina o arquivo e quais dados devem ser incluídos para configurá-lo.
Muitos arquivos, porém, apenas apontam para outros arquivos, e estão ligados através dos chamados links. Existem dois tipos de links: o hard link é exatamente o nome de um arquivo (sendo que um mesmo arquivo pode ter vários nomes); ele só será removido do disco rígido quando o último nome for removido. Já o soft link (ou link simbólico) é um pequeno arquivo especial, que contém um apontador para onde o arquivo real está localizado, ou seja, o link aponta para um outro arquivo, que pode ser inclusive de um outro tipo de sistema de arquivo. Para criar um link simbólico basta digitar, como superusuário:
# ln -s [arquivo_original] [link_para_arquivo] |
Para criar um link direto, basta retirar o parâmetro -s da linha anterior.
Após a descrição destes conceitos importantes, segue primeiramente uma lista com alguns diretórios importantes, e logo após alguns arquivos destes diretórios. Estes diretórios podem mudar de uma distribuição Linux para outra, mas basicamente seguem a estrutura abaixo.
-
Diretório /etc
-
init.d: diretório que contém scripts para a inicialização de serviços da máquina, que na verdade é um link simbólico para o diretório /etc/rc.d/init.d.
-
exports: arquivo que serve para controlar o acesso a sistema de arquivos que estão sendo exportados para clientes NFS.
-
X11: configurações relacionadas ao sistema de janelas X, como por exemplo configuração do teclado e comportamento de alguns programas no ambiente gráfico.
-
crontab: arquivo de configuração do cron, que é o servidor utilizado para executar serviços agendados.
-
passwd: contém informações sobre os usuários da máquina. Nesse arquivo ficam armazenados o nome do usuário, seu nome real, diretório pessoal, interpretador de comandos a ser usado e outras informações específicas do usuário.
-
group: parecido com o arquivo passwd, porém, trabalha com grupos de usuários ao invés de usuários individuais.
-
fstab: contém uma lista com os sistemas de arquivos e opções padrão para a montagem de sistema de arquivos.
-
mtab: contém a relação dos sistemas de arquivos atualmente montados, juntamente com opções de montagem e o estado em que se encontram.
-
inittab: arquivo de configuração dos níveis de execução (runlevel) do sistema.
-
printcap: contém as configuração para as impressoras ligadas ao sistema ou à rede. Nesses arquivos são configurados filtros e alguns outros recursos administrativos relativos a impressoras.
-
securetty: contém a relação de terminais considerados seguros. O superusuário só poderá acessar a máquina a partir desses terminais. Geralmente são listados apenas terminais acessíveis localmente.
-
modules.conf: arquivo de configuração dos módulos do kernel, composto por várias diretivas que adicionam, direcionam e carregam os módulos.
-
rc.local: este arquivo é um link simbólico para /etc/rc.d/rc.local. Ele é um script, tendo como principal função atualizar arquivos de mensagens de inicialização do sistema e do idioma, entre outros arquivos (verifica arquivos como o /etc/issue e o /etc/motd). Ele será executado depois de todos os scripts de inicialização.
-
rc.sysinit: executado no momento da inicialização do sistema, ele configura todas as informações necessárias para a utilização do sistema, como: detalhes de rede, parâmetros do kernel e mapa de teclado, entre outras.
-
shells: lista dos interpretadores de comando válidos. Alguns servidores e comandos restringem o acesso do usuário aos interpretadores de comando relacionados nesse arquivo.
-
-
Diretório /usr
-
X11R6: é um diretório contendo arquivos do sistema de janelas X. Esse diretório contém diversos outros arquivos pelos quais se espalham os arquivos do X.
-
bin: contém praticamente todos os comandos de usuários. Alguns outros podem ficar no diretório /bin ou, com menos freqüência, no diretório /usr/local/bin.
-
sbin: possui os comandos de administração do sistema que não necessitam estar no diretório raiz e que são exclusivos do superusuário.
-
local: é usado para armazenar os programas instalados localmente e que não se encontravam empacotados com o RPM.
-
share/doc: neste diretório se encontra a maioria da documentação disponível da distribuição, como páginas de manual (manpages) e arquivos Como Fazer (HOWTOs), entre outros.
-
-
Diretório /var
-
lock: contém arquivos de bloqueio. Muitos programas seguem uma convenção criando arquivos de bloqueio nesse diretório para sinalizar que estão usando um dispositivo específico (como o modem, por exemplo) ou um arquivo especial. Quando outros programas detectam a presença desse bloqueio, eles não usam o mesmo dispositivo ou arquivo.
-
log: possui os arquivos de registro e/ou históricos de programas. Os arquivos desse diretório tendem a crescer indefinidamente; isso faz com que se torne necessária uma limpeza periódica nesse diretório. No Conectiva Linux o aplicativo logrotate faz esse serviço automaticamente de acordo com configurações preestabelecidas ou configurações definidas pelo administrador.
-
spool: armazena as diversas filas de tarefas como e-mail, notícias, impressão, etc. Cada fila fica armazenada em seu próprio diretório.
-
-
Diretório /proc
-
cpuinfo: apresenta informações sobre o(s) processador(es), tais como fabricante, modelo e registradores, entre outras.
-
devices: mostra uma relação dos dispositivos atualmente configurados no kernel do sistema operacional.
-
interrupts: relaciona as interrupções em uso e outras informações a respeito dessas como, por exemplo, a quantidade de vezes que foram acessadas.
-
meminfo: arquivo com informações sobre compartilhamento e o uso de memória.
-
Permissões de Arquivos
Permissão é um conceito importantíssimo, principalmente para garantir a segurança do sistema contra acessos indevidos a arquivos importantes. Será mostrado nesta seção como são definidas as permissões em um sistema Linux.
Todo arquivo do sistema pertence a um dono e a um grupo, podendo pertencer somente a um usuário ou fazer parte de um grupo de vários usuários. Estes dois parâmetros (dono do arquivo e grupo ao qual o arquivo pertence) é que determinam as permissões do arquivo, por quem o arquivo foi criado, que permissões foram dadas pelo dono, quem poderá acessá-lo e a forma de acesso de que irão dispor todos aqueles que fizerem operações com o arquivo, entre outros. Vamos descrever brevemente como interpretar estas informações.
No Linux a implementação de permissões é feita para três grupos de usuários. São esses grupos: o dono do arquivo[3], o grupo de trabalho ao qual o arquivo pertence e, finalmente, os demais usuários que não se encaixam nos dois grupos anteriores. Esses dados podem ser visualizados através do comando ls -l e modificado através dos comandos chown, que muda o dono do arquivo e também o seu grupo; o comando chgrp é usado para mudar apenas o grupo do arquivo[4].
Como os dados são tratados como arquivos, mesmo que sejam apenas indicadores para dispositivos (por exemplo, /dev/mouse), as permissões fazem com que se possa proibir determinado usuário ou grupo de usuários de acessar algum recurso específico da máquina, como por exemplo recursos de áudio ou o acesso a um drive de disquetes. No entanto, o superusuário pode acessar qualquer arquivo ou dispositivo, independente de suas permissões.
Quando um arquivo é criado, ele recebe certos valores de propriedade, como o UID do dono (normalmente o criador do arquivo), o valor de propriedade do grupo GID (geralmente o grupo a que o dono pertence quando o arquivo é criado) e outros valores de permissão de acesso, derivados dos valores associados ao valor umask do dono, no momento da criação. Estes valores umask são definidos geralmente no arquivo /etc/profile com os seguintes valores:
-
Para o superusuário:
# umask 022
-
Para os demais usuários do sistema:
# umask 002
A umask funciona retirando permissões, ou seja, a permissão padrão do sistema seria 666, mas com um valor de 022, no caso do superusuário, teríamos 644 (666-022=644), o que significa que quando um arquivo for criado pelo superusuário ele vai ter suas permissões inicias em -rw-r-r--, permitindo escrita e leitura para o dono do arquivo e somente leitura ao grupo ao qual ele pertence e para os demais usuários do sistema. Já no caso dos usuários comuns do sistema, todo arquivo iniciará sua vida com permissões 664 (666-002=664), o que significa leitura e escrita para o dono e para o grupo (no formato absoluto será -rw-rw-r--) e aos outros usuários do sistema permite apenas leitura.
Pode-se verificar, através do exemplo abaixo, que existem vários dados importantes utilizados para identificar as características de um arquivo. Veja o Exemplo 4-1:
Exemplo 4-1. Informações Sobre um Arquivo
$ ls -l teste |
O primeiro bit do campo -rw-rw-r-- determina o seu tipo, pois tudo em um sistema Linux é tratado como se fosse arquivo, incluindo os diretórios, links e dispositivos do sistema. Os principais tipos e seus significados são:
-: atributo de arquivo.
d: quando se trata de um diretório.
l: o arquivo é um link simbólico.
b: dispositivos de bloco.
c: dispositivos de caractere.
s: trata-se de um socket, atribuído para arquivos de comunicação e memória.
t: sticky bit.
Sticky bit é um bit utilizado tanto para arquivos como para diretórios no Linux. Se for habilitado para um arquivo executável, enviará uma mensagem para que o kernel mantenha o código carregado em uma área de troca[5], mesmo depois de terminada a execução do arquivo. Isto causa uma melhora de desempenho, pois caso o arquivo venha ser executado novamente, ele já estará na área de troca.
Se o sticky bit for habilitado em um diretório, um usuário não terá privilégios para renomear ou apagar arquivos de outros usuários neste diretório, somente terá acesso aos seus próprios documentos. Porém, se as permissões forem modificadas, o usuário poderá ter acesso aos documentos de outros usuários também.
O restante do campo indica as permissões para cada grupo. Os tipos de permissões para arquivos são:
r: leitura (copiar, imprimir, visualizar).
w: escrita (mover, apagar, modificar).
x: execução (programas, scripts, diretórios).
-: sem permissão.
E para os diretórios:
r: permite que você liste o conteúdo do diretório.
w: permite que você crie, altere a apague arquivos no diretório.
x: permite que você efetue buscas no diretório.
-: sem permissões para o diretório.
Estas permissões podem ser aplicadas para:
u: o dono do arquivo (user).
g: um grupo de usuários ao qual o arquivo pertence (group).
o: todos os usuários que não estão incluídos em nenhuma das duas categorias anteriores (others ou outros).
a: todas as permissões ao mesmo tempo (u+g+o).
O campo com o número 1 pode ter dois significados. Se for um arquivo, este número indica quantos hard links estão sendo apontados para ele, e neste caso, existe apenas um só: o arquivo apontando para ele mesmo. Se for um diretório, indica quantos subdiretórios existem (incluindo o . e o ..). A seguir, os campos aluno e projeto mostram o nome do usuário e do grupo no qual o arquivo se encontra. Caso o usuário dono do arquivo ou o seu grupo não estejam adicionados ao sistema, serão visualizados os números de UID (User Identification) e GID (Group Identification) do arquivo.
Os últimos campos indicam o tamanho do arquivo, a data e o horário em que ele foi pela última vez modificado e, por fim, o nome do arquivo.
O dono do arquivo tem total controle sobre todos os seus parâmetros a qualquer hora; se um usuário não for o dono do arquivo mas pertencer ao grupo, poderá acessá-lo, mas não poderá restringir ou permitir acessos ao arquivo.
Se o usuário tem permissões de escrita no diretório e tentar apagar um arquivo que não tenha permissão de escrita, o sistema perguntará se ele confirma a exclusão do arquivo apesar do modo leitura. Caso tenha permissões de escrita no arquivo, o arquivo será apagado por padrão sem mostrar nenhuma mensagem de erro. Por outro lado, mesmo que se tenha permissões de escrita em um arquivo mas não se tenha permissões de escrita em um diretório, a exclusão do arquivo será negada.
Isto mostra que é levada mais em consideração a permissão de acesso do diretório do que as permissões dos arquivos e subdiretórios que ele contém. Esta característica é muitas vezes ignorada por muitas pessoas e expõe o sistema a riscos de segurança. Imagine o problema em que algum usuário que não tenha permissão de escrita em um arquivo mas que a tenha no diretório pode causar em um sistema mal administrado.
Para modificar permissões em grupos e arquivos utiliza-se os comandos chown e chgrp. Observe o Exemplo 4-2:
Exemplo 4-2. Mudando o Dono e o Grupo de um Arquivo
-
$ l arquivo
-rw-rw-r-- dono grupo arquivo
-
$ chown prop arquivo
$ l arquivo
-rw-rw-r-- prop grupo arquivo
-
$ chgrp users arquivo
$ l arquivo
-rw-rw-r-- prop users arquivo
-
$ chown dono.grupo arquivo
$ l arquivo
-rw-rw-r-- dono grupo arquivo
O exemplo anterior é apenas fictício, mas observe a seqüência em que os comandos foram aplicados até restaurar o arquivo ao seu estado original. As mudanças aplicadas em diretórios também podem ser feitas recursivamente, ou seja, alterando todos os arquivos e diretórios contidos no diretório. Para isso, basta usar os comandos chown e chgrp com o parâmetro -R.
Além destas permissões, existe uma permissão especial que permite que usuários possam executar arquivos de outros donos, com as permissões destes últimos. É o chamado o suid bit[6]. Veja o Exemplo 4-3, que mostra um exemplo de como o suid bit pode ser utilizado:
Com esta linha de comando, o arquivo teste.sh pode ser executado por qualquer usuário (parâmetro a - all), utilizando as permissões do dono do arquivo.
Nota: Além da identificação do usuário para a execução de um arquivo, esta identificação pode ser configurada também para um grupo de usuários (SGID). Veja a página de manual do comando chmod para mais detalhes (man chmod).
Note, portanto, que o sistema Linux representa praticamente tudo na forma de arquivos, o que agiliza a localização e a manutenção de problemas, além de manter um padrão entre todas as distribuições Linux.