Capítulo 7. Segurança no Servidor
Segurança é um tópico bastante abrangente, que rende livros inteiros. Justamente por isto, o propósito deste capítulo não é ser um guia absoluto de segurança, mas mostrar como aumentar a segurança de seu Conectiva Linux e explicar como funcionam alguns componentes básicos.
Visão Geral sobre Segurança
Atualmente, conectar redes locais à Internet é algo bastante comum e, embora isto possa trazer vantagens, também pode trazer vários problemas. Infelizmente, fazer parte da Internet significa estar exposto a uma grande variedade de ameaças, o que obriga todo e qualquer administrador a preocupar-se com a segurança de seus sistemas. Enquanto redes existem para facilitar o acesso a computadores, procedimentos de segurança existem para controlar este acesso.
O primeiro conceito relacionado a segurança é: "não existe sistema completamente seguro". O que é possível fazer é dificultar a invasão em sua máquina e, caso uma invasão ocorra, conseguir descobrir como ela ocorreu e tomar medidas preventivas. O trabalho necessário para proteger o seu sistema dependerá basicamente do que você tem para proteger e o quão importante é proteger este sistema.
Note que, de um modo geral, quanto mais seguro você tornar o seu sistema, mais complexa será sua utilização, pois existirão várias restrições de uso. É imprescindível usar o bom senso na hora de aplicar as medidas de segurança, para evitar que a terapia seja pior que a doença.
Antes de tomar qualquer atitude relacionada ao aumento da segurança de seu sistema, você deve saber o que está sendo protegido, por que e quanto vale esta informação. Além disso, é necessário verificar a que tipo de ameaças seu sistema está exposto. A RFC 1244, intitulada Site Security Handbook, por Holbrook Reynold e outros, identifica três tipos distintos de ameaças de segurança geralmente associadas à conectividade em rede:
- Acesso não autorizado:
-
Acesso ao sistema por uma pessoa não autorizada.
- Revelação de informações:
-
Qualquer problema relacionado ao acesso a informações valiosas ou confidenciais por pessoas que não deveriam acessá-las.
- Negação de Serviço:
-
Também conhecido como Denial of Service - DoS - relacionado a qualquer problema que torne impossível ou bastante difícil continuar utilizando o sistema de maneira produtiva.
Dependendo do sistema em questão, estas ameaças podem ser mais ou menos importantes. Por exemplo, para um órgão governamental ou empresa da área de tecnologia, acessos não autorizados podem desacreditá-los perante o público e/ou clientes. Já para a grande maioria das empresas, acesso não autorizado não é um grande problema, se não envolver uma das ameaças: revelação de informações e negação de serviço.
A extensão do problema em casos de revelação de informação varia de acordo com a informação que pode ser comprometida. Embora seja fato notório que informações sigilosas jamais devam permanecer armazenadas em máquinas conectadas à Internet, em alguns casos certos tipos de informação, como informações pessoais de clientes e/ou números de cartões de crédito, podem ser necessários em aplicações de comércio eletrônico, por exemplo. Neste tipo de caso, o cuidado deve ser redobrado.
A negação de serviço pode causar grandes prejuízos a empresas que conectam sistemas de missão crítica à Internet. Na verdade, as vantagens devem ser muito bem avaliadas antes de conectar este tipo de sistema à Internet, pois, dependendo do caso, esta conexão pode parar uma empresa por inteiro. Geralmente servidores menores são conectados à Internet, possivelmente acessando informações de um servidor principal através de um modo mais seguro.
Obviamente que, se a necessidade é justamente prestar um serviço na Internet, todos estes riscos existirão. Para diminuí-los é preciso tomar algumas precauções, como desabilitar os serviços desnecessários, utilizar controle de acesso através de ferramentas como o tcp_wrappers, instalar e configurar um firewall entre sua rede local e redes externas (geralmente entre sua rede local e a Internet). É também importante analisar constantemente os logs e a integridade de arquivos importantes do sistema, além de analisar alternativas como a instalação de um servidor Kerberos. O Conectiva Linux conta com as ferramentas necessárias para ajudá-lo na tarefa de tornar seu sistema mais seguro.
Finalizando esta introdução, manter um sistema seguro envolve vários procedimentos, sendo que o mais importante é manter uma monitoração constante do sistema, para notar qualquer anormalidade antes que ela se torne um problema grave.
Particionamento do HD do Servidor
No Linux, e em todos os sistemas UNIX, existe o que se chama de transparência de localidade. O diretório /usr, por exemplo, pode ser local da máquina, ou montado via NFS de um servidor que está em outro lugar. Para todos os efeitos, é como se fosse local. Assim como esse diretório pode estar em outra máquina, ele também pode estar em outro meio físico, como um segundo disco rígido ou uma outra partição no mesmo disco.
Há várias vantagens, e algumas poucas desvantagens, em se usar um esquema de particionamento. Serão vistos aqui alguns aspectos do particionamento do disco rígido de um servidor Linux, tendo em vista aspectos de segurança.
Disco Cheio
A proteção mais básica que se consegue com um bom esquema de particionamento é com relação ao problema de disco cheio. Para partições que armazenam dados de usuários, como a /home ou a de e-mail, isso pode ser contornado até certo ponto com o uso de quotas (ver a seguir). Mas, por exemplo, o diretório de logs, /var/log, é usado pelo sistema, e não por um usuário específico (usuário aqui no sentido de pessoa). Se não houvesse particionamento, o único limite para o tamanho desses arquivos seria o HD inteiro. Se, por exemplo, um ataque inundar os logs, se o disco estiver corretamente particionado isso somente afetará a partição dos logs: os usuários ainda terão o mesmo espaço livre no /home, o espaço para programas continuará o mesmo, etc. O mesmo vale para o outro sentido. Se não houver sistema de quotas, usuários poderão criar arquivos de qualquer tamanho e simplesmente acabar com o espaço em disco. Se houver particionamento, no máximo acabarão com o espaço em disco daquela partição.
Quotas
No Linux, quotas de disco são aplicadas por partição. Se houver somente uma partição no disco (a partição /, por exemplo), as quotas somente se aplicarão a ela por inteiro. Não há como definir quotas para diretórios específicos, a não ser que eles sejam pontos de montagem de alguma outra partição. Usando quotas, podemos definir alguns limites interessantes para usuários e/ou grupos. O sistema de quotas trabalha com os seguintes limites:
-
soft limit: ao atingir este limite, o usuário infrator é avisado via e-mail e possui um período de tempo para voltar a ficar abaixo do limite;
-
grace period: período em que o usuário pode ficar acima do soft limit. Após este período, o usuário não poderá mais criar arquivos nesta partição, devendo remover algo para voltar a ficar abaixo do limite;
-
hard limit: é o limite que jamais será ultrapassado. Por exemplo, um usuário pode ultrapassar o soft limit e receber o aviso, mas continuar a aumentar o espaço ocupado no disco, ignorando o aviso. Mas do hard limit ele não poderá passar.
O pacote quotas possui diversos utilitários para manipular as quotas, mas o Linuxconf possui uma interface bastante agradável para fazer a mesma coisa. Antes de poder usar as quotas é necessário ativar seu suporte na hora de montar o sistema de arquivos. Na prática, o Linuxconf alterará o /etc/fstab para isso, e depois as funções de quotas poderão ser manipuladas à vontade.
Opções especiais de Montagem
Esta é a parte do particionamento que é mais interessante do ponto de vista de segurança. Pode-se fazer com que o sistema trate certos arquivos de forma diferente com uma série de opções. As opções de montagem podem ser fornecidas como parâmetro para o comando mount ou direto no arquivo /etc/fstab:
Via linha de comando: |
A Tabela 7-1 ilustra algumas opções existentes para sistemas de arquivos dos tipos mais comuns (como ext2, ext3 e reiserfs). Outras, marcadas com um asterisco (*), também estão disponíveis para qualquer sistema de arquivos.
Tabela 7-1. Opções para sistemas de arquivos ext2
|
Opção |
Efeito |
|---|---|
|
nodev(*) |
Dispositivos especiais de bloco ou caractere do sistema de arquivos não serão interpretados se nodev estiver especificado. |
|
nosuid(*) |
Bits SUID e SGID não terão efeito. Se um usuário comum executar um programa SUID ou SGID que force a troca para outro usuário, receberá o erro de permissão negada. |
|
noexec(*) |
Não permite a execução de binários. Note que scripts ainda poderão ser executados usando, por exemplo, bash foo.sh em vez de ./foo.sh (há ainda outras formas de contornar esta proibição, como, por exemplo, utilizar o loader ld.so). |
|
ro, rw |
A partição será montada somente para leitura (read-only) ou somente para escrita (read-write), respectivamente. |
|
user, nouser(*) |
A partição pode (user) ou não (nouser) ser montada por usuários que não sejam root. |
|
usrquota |
Ativa a quota de disco por usuário. |
|
grpquota |
Ativa a quota de disco por grupo. |
|
grpid |
Com esta opção ativada, arquivos criados nesta partição terão o group ID do diretório onde eles foram criados. Caso contrário, terão o group ID do processo que os criou. Este comportamento também pode ser obtido se o bit SGID do diretório estiver ligado. |
|
sync(*) |
Toda a operação de entrada e saída nesta partição será síncrona. Isto tornará a escrita nesta partição mais lenta, mas também menos suscetível a problemas caso, por exemplo, falte energia elétrica logo após a operação de escrita. Numa operação assíncrona, os dados provavelmente ainda não foram escritos neste exemplo. |
Estas opções são muito interessantes e se aplicam a diversas partições do nosso servidor. A seguir serão mostrados alguns exemplos de uso dessas opções em diferentes partições:
- /usr: nodev,ro
-
Nesta partição se encontram normalmente os programas do sistema. De forma alguma devem existir arquivos de dispositivo aqui, por isso foi colocada a opção nodev. Também não deve ser necessário escrever nesta partição, salvo instalação ou remoção de algum programa. Nestes casos, ela deve ser remontada com a opção rw e depois novamente remontada com a opção read-only. Note que os direitos dos diretórios por si só já não permitem a qualquer usuário realizar operações de escrita ali, mas o read-only é uma medida adicional, pois nem o usuário root poderá alterar algo ali antes de remontar a partição como read-write.
- /dev: nosuid,noexec
-
Estas duas opções são até certo ponto redundantes, mas mesmo assim é bom especificá-las. A primeira, nosuid, não permite a execução de binários SUID ou SGID. A segunda não permite a execução de qualquer binário. Na verdade, há o script MAKEDEV neste diretório, mas ele ainda poderá ser executado usando bash ./MAKEDEV.
- /var: noexec,nosuid,nodev
-
O diretório /var é usado para guardar e-mails, arquivos de log, dados de programas (banco de dados RPM, por exemplo) e outras coisas. Mas /var/tmp pode ser utilizado pelo processo de compilação de um pacote RPM para guardar os scripts que serão usados. Se noexec for usado, esses scripts não funcionarão. Portanto, use noexec com cuidado. Alguma aplicação pode ter o funcionamento comprometido. Uma outra opção é colocar /var/tmp em uma outra partição, e permitir a execução nesta.
- /tmp: noexec,nosuid,nodev
-
O diretório /tmp pode ser usado para qualquer coisa basicamente. Scripts temporários podem ser colocados ali, por exemplo. Como é um diretório com permissões de escrita para qualquer usuário, basicamente deve-se proibir a execução de binários SUID/SGID através da opção nosuid. Também não há motivo para se usar arquivos de dispositivos aqui, por isso o uso da opção nodev. Eventualmente noexec também pode ser usado, mas alguns programas podem necessitar de um /tmp que permita a execução de programas.
- /boot: noexec,nosuid,nodev,ro
-
Esta partição possui bem pouca atividade no sistema. Na verdade, após o boot (que nem sabe o sistema de arquivos que roda ali, quanto menos opções de montagem da partição), ela só é usada quando se faz uma atualização do kernel ou da imagem de disco inicial (initrd). Nada deve ser executado ali, arquivos de dispositivos não são bem-vindos e ela deve ser montada read-only. Quando se fizer uma atualização do kernel, basta remontá-la com a opção read-write.
- /home: nosuid,nodev,noexec
-
Aqui depende do administrador da máquina quais das opções acima serão usadas. Recomenda-se pelo menos usar nosuid e nodev. Pode-se ainda usar a opção noexec, mas o usuário sempre poderá executar binários, bastando, por exemplo, copiá-los para o /tmp[1].
Segurança básica local
Nesta parte será visto como funciona a autenticação em uma máquina Linux: que tipos de senhas pode-se usar (com que tipo de criptografia), como verificar se as senhas são boas ou fáceis e como funcionam as permissões do sistema de arquivos, tudo isso com vários exemplos. Além disso, também serão vistos os logs ou registros do sistema: onde eles são gerados, como organizá-los, etc.
PAM
PAM é a parte principal da autenticação em um sistema Linux. PAM significa Pluggable Authentication Modules ou Módulos de Autenticação Plugáveis/Modulares.
Originalmente a autenticação no Linux era apenas via senhas criptografadas armazenadas em um arquivo local chamado /etc/passwd. Um programa como o login pedia o nome do usuário e a senha, criptografava a senha e comparava o resultado com o armazenado naquele arquivo. Se fossem iguais, garantia o acesso à máquina. Caso contrário, retornava erro de autenticação. Isto até funciona muito bem para o programa login, mas, suponha que agora deseja-se usar isso também para autenticação remota, ou seja, a base de usuários não está mais na mesma máquina, mas sim em alguma outra máquina da rede, o chamado servidor de autenticação. Será preciso mudar o programa login para que ele também suporte esse tipo de autenticação remota.
Suponha também que surgiu um novo algoritmo de criptografia, muito mais avançado, mais rápido, criptografa melhor, etc., sendo que o desejo é usar esse novo algoritmo. Deve-se, então, mudar novamente o programa login para que ele suporte este novo algoritmo também. No Linux, muitos programas utilizam algum tipo de autenticação de usuários. Imagine se todos eles tivessem que ser reescritos cada vez que se mudasse algum dos critérios de autenticação.
Para resolver este tipo de problema, a Sun® criou o PAM há alguns anos e liberou as especificações em forma de RFC. O Linux derivou sua implementação do PAM a partir deste documento. Com PAM, o aplicativo login deste exemplo teria que ser reescrito apenas uma vez, justamente para suportar PAM. A partir de então, o aplicativo delega a responsabilidade da autenticação para o PAM e não se envolve mais com isso.
Voltando ao exemplo anterior, no caso de se querer utilizar um outro algoritmo de criptografia para as senhas, basta que o módulo PAM seja modificado para que todos os aplicativos automaticamente e de forma transparente passem a usufruir desta nova forma de autenticação. PAM possui uma outra vantagem: é possível configurar a autenticação de forma individual para cada aplicativo. Com isto é possível fazer com que, por exemplo, um usuário comum possa usar os dispositivos de áudio do computador desde que tenha se logado na máquina através do console. Se o login não tiver sido feito no console (por exemplo, é um login remoto via SSH), este tipo de acesso ao hardware será negado.
Na verdade, PAM vai um pouco além da autenticação. Os módulos podem ser divididos em quatro classes:
- auth:
-
É a parte que verifica que o usuário é realmente quem ele diz que é. Pode ser bem simples, pedindo apenas por um nome e uma senha, ou utilizando autenticação biométrica, por exemplo (como uma impressão de voz, uma imagem da retina ou impressão digital).
- account:
-
Esta parte verifica se o usuário em questão está autorizado a utilizar este serviço ao qual ele está se autenticando. Os módulos aqui podem verificar por horário, dia da semana, origem do login, login simultâneo, etc.
- passwd:
-
Este serviço é usado quando se deseja mudar a senha. Por exemplo, aqui podem ser colocados módulos que verificam se a senha é forte ou fraca.
- session:
-
Por fim, a parte session fica encarregada de fazer o que for necessário para criar o ambiente do usuário. Por exemplo, fornecer o acesso a alguns dispositivos locais como o de áudio ou CD-ROM, montar sistemas de arquivos ou simplesmente fazer o registro do evento nos arquivos de log do sistema.
Um módulo PAM pode ou não conter todas estas funções. O módulo pam_unix, por exemplo, pode ser usado nestes quatro tipos e possui ações diferentes em cada uma das situações, enquanto que pam_console é normalmente usado apenas como session.
Instalação
Os módulos PAM já vêm instalados por padrão no Conectiva Linux. Você pode verificar utilizando o comando apt-getprocurando, ou na lista de pacotes instalados do Synaptic, pelo pacote pam, sendo que a documentação está no pacote com nome pam-doc.
PAM no Linux
Praticamente todos os aplicativos do Linux que requerem algum tipo de autenticação suportam PAM. Na verdade, não funcionam sem PAM. Toda a configuração está localizada no diretório /etc/pam.d. Quando um aplicativo suporta PAM, ele necessita de um arquivo de configuração neste diretório. A Figura 7-1 ilustra como funciona a autenticação com PAM usando o programa login como exemplo:
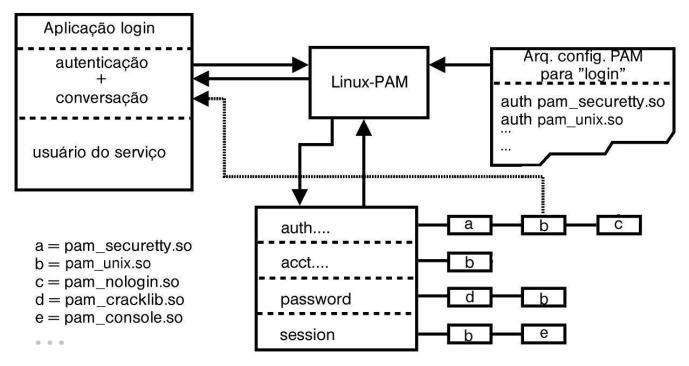
Um programa com suporte a PAM possui duas interfaces com a biblioteca: a de autenticação e a de conversação. A interface de autenticação é por onde a aplicação pede que o PAM valide o usuário. A de conversação é usada pelos módulos que, por exemplo, precisem passar alguma informação para o usuário, como um prompt, ou um aviso de que a senha expirou. Isso é tudo o que a aplicação sabe sobre o processo de autenticação feito pelo PAM. A conversação está ilustrada na figura no módulo pam_unix (b).
Nota: Somente instalações mais recentes utilizam o módulo pam_unix para praticamente todos os serviços. Versões antigas do Conectiva Linux podem, ainda, utilizar o módulo pam_pwdb.so.
A biblioteca PAM vai procurar o arquivo de configuração da aplicação login. Este arquivo é /etc/pam.d/login e vai dizer quais módulos devem ser usados e com que parâmetros. Este arquivo está reproduzido a seguir:
#%PAM-1.0 |
| Atenção |
|
É importante ressaltar que este arquivo é somente um exemplo, podendo ser diferente do que estiver contido em sua máquina. |
Este arquivo de configuração lista os módulos PAM que este programa (login) deve usar, e eles estão representados na figura através de letras. Estes módulos serão carregados e executados na ordem em que estiverem no arquivo de configuração. Note que um módulo pode aproveitar uma informação de um módulo anterior, como normalmente é feito para o nome de acesso/senha. Isso é usado para não pedir a mesma informação novamente para o usuário.
A primeira coluna em um arquivo de configuração PAM representa o tipo de módulo: auth, account, password ou session. Neste exemplo, todos estão presentes, mas isto não é obrigatório. Se um programa não tiver suporte à troca de senha, o tipo password não é usado.
A segunda coluna define o controle para o seu respectivo módulo. O resultado de cada módulo pode influenciar de diversas formas no resultado do processo de autenticação geral. Há algumas categorias:
- required:
-
O resultado deste módulo influencia diretamente o resultado final. Uma falha em um módulo deste tipo só aparecerá para o usuário após todos os outros módulos desta classe serem executados.
- requisite:
-
Semelhante a required, mas os outros módulos não são executados e o controle volta imediatamente para o aplicativo em caso de falha.
- sufficient:
-
A falha deste módulo não implica em falha da autenticação como um todo. Se o módulo falhar, o próximo da classe é executado. Se não houver próximo, então a classe retorna com sucesso. Se, por outro lado, o módulo terminar com sucesso, então os módulos seguintes dessa classe não serão executados.
- optional:
-
Os módulos marcados como optional praticamente não influenciam o resultado da autenticação como um todo. Eles apenas terão alguma influência caso os módulos anteriores da mesma classe não apresentem um resultado definitivo.
Por fim, a terceira coluna define o nome do módulo que será usado e seus parâmetros. Todos os módulos estão documentados no diretório /usr/share/doc/pam-doc-versão (pacote pam-doc). Será visto aqui apenas ilustrar como funcionam os usados no programa login.
Em primeiro lugar, observa-se que todos os módulos possuem o parâmetro required, ou seja, não podem falhar (com exceção do pam_console).
pam_securetty
Este é o primeiro módulo a ser usado e ele simplesmente verifica o terminal de onde o login está ocorrendo. Este módulo não usa parâmetros, mas possui um arquivo de configuração: /etc/securetty. Neste arquivo são listados os terminais a partir dos quais o usuário root pode fazer login, ou seja, são os terminais considerados seguros. Apesar do nome terminais, conexões remotas também são controladas por aqui, pois elas alocam pseudo-terminais (telnet, etc). O módulo retorna sucesso para qualquer usuário diferente de root e, se for root, somente se o terminal de onde está vindo o login estiver listado em /etc/securetty. Para permitir o login de root via telnet, por exemplo, basta acrescentar ao /etc/securetty pts/0. Note que isto somente liberará o pseudo-terminal pts/0. Veja no exemplo seguir:
$ telnet localhost |
A primeira conexão telnet ganhou o pseudo-terminal pts/0. Já a segunda teve o pts/1 alocada para si, e este pseudo-terminal não estava listado no arquivo /etc/securetty. Portanto, o acesso não foi autorizado. Isto não funciona com SSH, por exemplo, pois o módulo pam_securetty não está presente ali. O SSH possui seu próprio mecanismo de acesso para o usuário root, mas nada impede que o pam_securetty seja acrescentado no arquivo PAM. O módulo pam_securetty também pode ser usado para controlar o login a partir do ambiente gráfico, por exemplo. Basta acrescentar o módulo ao arquivo /etc/pam.d/kde (se o kdm estiver sendo usado para login gráfico). A linha a ser acrescentada ao arquivo /etc/securetty (além de se acrescentar pam_securetty aos respectivos arquivos PAM) é :0. Isto para o display zero. Para permitir o login de root em outros displays, a sintaxe é :DISPLAY .
O objetivo original deste módulo é o de evitar o login do root em terminais inseguros. Este conceito de terminais foi estendido ao login remoto (através dos pseudo-terminais).
pam_unix
O módulo pam_unix é o módulo principal da autenticação do programa login e da maioria dos serviços que utilizam PAM. Ele vai pedir um nome de usuário e uma senha e verificar se estão corretos. Como tal, o módulo utiliza a função de conversação para interrogar o usuário e pegar as informações desejadas.
Este módulo aceita alguns parâmetros, conforme seu uso (auth, account, etc.):
-
shadow: avisa o módulo que o sistema está utilizando senhas shadow.
-
nullok: permite o uso de senhas em branco. Note que, mesmo que a senha seja em branco (nula), o usuário não conseguirá fazer login se não existir nullok na linha auth para este módulo.
-
md5: usa criptografia (hash) md5 em vez do crypt padrão. Pode ser usado na linha password.
-
use_authtok: indica que o módulo deve usar a autenticação já fornecida para os módulos anteriores, de forma a não interrogar o usuário novamente. Alguns outros módulos suportam o parâmetro use_first_pass, que funciona da mesma forma. Existe ainda o try_first_pass, que primeiro tenta as mesmas credenciais: se houver falha, pede novamente para o usuário. O use_first_pass não faz esse novo pedido caso ocorra uma falha.
O try_first_pass será usado mais adiante quando for mostrada a autenticação via LDAP. O módulo pam_unix é bem genérico por usar as funções da glibc e, portanto, suporta NIS, LDAP, arquivos texto, arquivos binários e qualquer outra coisa que a glibc vier a suportar (através de NSS).
pam_nologin
O módulo pam_nologin é bastante simples, e muito útil. É uma forma rápida de desabilitar o login de qualquer usuário que não seja o root. Para isto, basta criar o arquivo /etc/nologin. Existindo este arquivo, o módulo pam_nologin vai sempre retornar ERRO para usuários diferentes de root e exibir o conteúdo de /etc/nologin (onde se deve colocar o motivo da proibição), ou seja, só o usuário root consegue se logar na máquina. Quando o arquivo for removido, a operação voltará ao normal, com usuários comuns podendo se logar novamente. Isto pode ser útil quando se quer fazer alguma manutenção no sistema, por exemplo, situação em que logins de usuários são indesejáveis. Alguns aplicativos do próprio Linux também podem criar este arquivo e depois removê-lo quando alguma operação crítica for concluída.
Note que os usuários que já estiverem logados na máquina não são afetados pela criação ou remoção do arquivo /etc/nologin.
pam_cracklib
Este módulo é especialmente importante para a segurança pró-ativa. Colocado apenas na classe password, o módulo vai verificar a senha do usuário antes que ela seja trocada. Se for uma senha considerada fraca, ela será rejeitada e o usuário não conseguirá trocar a senha. As verificações que o módulo faz atualmente são:
-
palíndromo: a nova senha é um palíndromo (frase que tem o mesmo sentido da esquerda para a direita ou ao contrário)?
-
caixa: a senha nova é a antiga com apenas mudanças de maiúsculas/minúsculas?
-
similar: a nova senha é muito similar à antiga? Esta verificação pode ser controlada por um parâmetro que indica o número mínimo de caracteres diferentes que a senha nova deve ter em relação à senha antiga. O valor padrão é 10 ou metade do tamanho da senha atual, o que for menor.
-
Senha repetida: se existir o arquivo /etc/security/opasswd com as senhas anteriores do usuário, o módulo pam_cracklib vai também verificar se a senha nova já não foi usada anteriormente. Esse arquivo de senhas antigas é atualmente gerado apenas pelo módulo pam_unix, embora exista uma discussão para se criar um módulo específico para esta tarefa (algo como pam_saveoldpass) e remover esta funcionalidade do módulo pam_unix.
Os parâmetros normalmente utilizados com o módulo cracklib são:
- retry=N
-
"N" é o número de tentativas que o usuário poderá fazer para fornecer uma senha considerada boa.
- difok=N
-
"N" é o número de letras diferentes que a senha nova deve ter em relação à senha antiga. Este parâmetro controla o comportamento da verificação do tipo similar, visto há pouco. O valor padrão é 10 (e este é o valor alterado por "N" ou metade do tamanho da senha atual), aquele que for o menor.
- minlen=N
-
Tamanho mínimo da nova senha mais um. Além de contar a quantidade de caracteres da senha nova, créditos também podem ser fornecidos com base na quantidade de algarismos, caracteres maiúsculos/minúsculos e símbolos. Ou seja, se o valor de minlen for 10, o usuário pode usar uma senha com menos do que 10 caracteres, desde que, somando a quantidade de caracteres mais os créditos, o valor final ultrapasse 10. Por exemplo:
password required /lib/security/pam_cracklib.so retry=3 minlen=10
Especifica-se um tamanho mínimo de 9 para a senha nova. Portanto, uma senha igual a senharuim vai funcionar (possui nove caracteres). Mas uma senha igual a am0Bb$ também funcionará, apesar de possuir apenas 6 caracteres, isto por causa dos créditos.
am0Bb$=>6+1(B, maiúscula)+1(0, dígito)+1($, símbolo)= 9=>OK,
passará.Por outro lado:
am0Bbd => 6 + 1(B, maiúscula) + 1(0, dígito) = 8 => não passará.
Por padrão, cada um dos tipos de variação da senha (minúsculo, maiúsculo, algarismo e símbolo) conta no máximo um crédito, ou seja:
am0b9$ => 6 + 1(0, dígito) + 1 ($, símbolo) = 8 => não passa
Note que o uso de dois algarismos não ajudou em termos de créditos. Mas isto pode ser mudado se for passado um outro parâmetro para o módulo:
password required /lib/security/pam_cracklib.so retry=3 \
minlen=10 dcredit=2Através do parâmetro dcredit estipula-se que será tolerado no máximo dois créditos provenientes de algarismos na senha. Com esta alteração, a senha am0b9$ passará como válida pois usa dois algarismos e então atingirá o mínimo de 9 exigido por esta configuração do módulo. Estes parâmetros de créditos também existem para as outras variantes:
-
dcredit: número máximo de créditos fornecidos provenientes do uso de algarismos na senha. O valor padrão é 1.
-
ucredit: número máximo de créditos fornecidos provenientes do uso de letras maiúsculas na senha. O valor padrão é 1.
-
lcredit: número máximo de créditos fornecidos provenientes do uso de letras minúsculas na senha. O valor padrão é 1.
-
ocredit: número máximo de créditos fornecidos provenientes do uso de outros caracteres (símbolos) na senha. O valor padrão é 1.
-
pam_console
O objetivo do módulo pam_console é permitir ao usuário local (ou seja, no console, fisicamente na máquina) o acesso a diversos dispositivos normalmente restritos ao superusuário, como placa de som, dispositivo de disquete e também permitir ao usuário comum (local) executar certas tarefas, como desligar o computador, entrar no ambiente gráfico ou mesmo instalar pacotes RPM.
Essa capacidade adicional é fornecida ao usuário no seu primeiro login é removida após o último logout, e se dá através da modificação das permissões de alguns dispositivos e também através de autenticação.
Diz-se que o primeiro usuário que fizer login no console "ganha" o console e as permissões definidas no arquivo de configuração /etc/security/console.perms. Quando um usuário possui o console, um arquivo de lock é criado em /var/lock com o nome console.lock. O conteúdo do arquivo é o nome do usuário que possui o console. Se um outro usuário local fizer um login, ele não receberá o console, pois já existe um bloqueio indicando que o console pertence a outro usuário. Quando o usuário do console sair, o arquivo de lock será removido e o console novamente ficará à disposição do primeiro usuário (não root) que fizer o login.
Quando um usuário recebe o console, várias permissões são alteradas no sistema de arquivos, conforme indicado no arquivo de configuração deste módulo PAM. Note que este módulo está como optional, ou seja, não é usado para o sucesso ou não da autenticação do usuário. Isso é necessário, pois ele pode falhar (um outro usuário já possui o console, por exemplo).
A seguir, um arquivo de configuração típico (sem os comentários maiores):
# file classes -- these are regular expressions |
Em primeiro lugar, esta configuração define classes de arquivos e classes de dispositivos. Por fim, especifica como devem ser as permissões quando o usuário ganhou o console e quando faz logout. Por exemplo, os dispositivos do tipo floppy devem ter permissão 0660 com o dono sendo o usuário (o grupo não é alterado), e 0660 com donos root.floppy após o logout do usuário. Este tipo de esquema de permissões permite, por exemplo, que o usuário formate um disquete sem que seja necessário obter direitos de root na máquina.
Usando LDAP juntamente com PAM
Aqui será mostrado um exemplo rápido de como modificar o arquivo de configuração PAM para o programa login passar a suportar LDAP também. Note que isto não é suficiente para se ter um sistema completamente dependente do LDAP, para isso ainda é necessário o módulo nss_ldap, que nada tem a ver com PAM. O arquivo modificado fica da seguinte forma:
#%PAM-1.0 |
O módulo pam_securetty fica inalterado, pois ainda deseja-se controlar os terminais por onde o usuário root pode fazer login. Na verdade, o usuário root nem estará no banco de dados LDAP(usuários de sistema devem sempre ser locais). O mesmo para o módulo pam_nologin: permanece inalterado.
Existem, portanto dois módulos responsáveis pela autenticação: pam_unix e o módulo pam_ldap; deseja-se que usuários locais e remotos possam se autenticar nesta máquina. Para usá-los simultaneamente, colocam-se flags de controle.
Primeiramente, coloca-se o módulo pam_unix, pois se o usuário for local, poupa-se uma consulta ao servidor LDAP. Deve-se marcar este módulo como sufficient, ou seja, se ele for bem-sucedido (se o usuário for local e a senha estiver correta) então nenhum outro módulo desta classe (auth) será executado. Se o resultado não for OK (o usuário só existe no LDAP, ou então ele errou a senha), então o próximo módulo será tentado.
O módulo seguinte é justamente o pam_ldap. Nesta configuração coloca-se o parâmetro required, ou seja, se ele falhar, a autenticação como um todo falha também. Para não pedir a senha novamente para o usuário, aproveita-se a senha já fornecida antes e utiliza-se o parâmetro use_first_pass. Este parâmetro diz para o módulo pam_ldap para pegar a senha fornecida anteriormente. Se ela estiver incorreta, o módulo falha. Se fosse usado, por exemplo, o parâmetro try_first_pass em seu lugar, no caso de haver falha o módulo pam_ldap novamente pediria a senha para o usuário.
O mesmo truque do sufficient e required pode ser aplicado às outras classes: account, password e session. A classe session possui ainda uma pequena alteração no posicionamento do módulo pam_console. Como nada mais é executado após um módulo marcado como sufficient ter sido bem-sucedido, o pam_console não seria chamado se ficasse no fim do arquivo, como na configuração original para o programa login. Assim, ele é colocado no início.
Outros módulos interessantes
Existem diversos módulos PAM em uma distribuição Linux. Nem todos são usados, muitos são desconhecidos. Serão mostrados aqui alguns dos mais interessantes, do ponto de vista de segurança. Todos estes módulos estão bem descritos na documentação; veja em /usr/share/doc/pam-doc-versão mais detalhes sobre todos os módulos.
pam_deny, pam_warn
Estes dois módulos são úteis para se adotar o que é chamado de fail-safe. Como já foi visto, cada programa que suporta PAM deve ter seu respectivo arquivo de configuração no diretório /etc/pam.d. Se o arquivo não existir, o PAM vai abrir o arquivo other. É interessante que este arquivo esteja da seguinte forma:
# default configuration: /etc/pam.d/other |
O módulo pam_deny simplesmente vai sempre retornar erro. O problema é que ele não faz registros, e é aí que entra o pam_warn, cujo único objetivo é colocar uma mensagem no log do sistema. Um exemplo típico de log é ilustrado abaixo:
mar 19 10:53:51 kepler PAM-warn[8365]: service: su \ |
Para gerar este log, foi removido o arquivo /etc/pam.d/su e, como usuário comum, deve-se tentar executar o comando su:
$ su |
Se o arquivo other não tivesse o pam_warn, nada seria registrado nos logs do sistema.
pam_access
O módulo pam_access pode ser usado para controlar quais usuários podem fazer login de qual local (terminal, remoto, domínio, etc.). Alguns servidores, como o openssh, já possuem um controle parecido embutido, mas também podem usufruir deste módulo. O arquivo de configuração do módulo pam_access é /etc/security/access.conf e contém alguns exemplos. A sintaxe é bastante simples. Por exemplo, a linha abaixo permite o login do usuário usuario1 (ou de usuários do grupo grupo1) apenas a partir dos terminais tty3 e tty4. O resto (inclusive logins remotos) fica negado:
- : usuario1 : ALL EXCEPT tty3 tty4 |
Note que somente alterar o arquivo /etc/security/access.conf não é o suficiente, isto é, o módulo pam_access precisa ser usado. Este módulo entra na categoria account e deve ser usado da seguinte forma:
account required /lib/security/pam_access.so |
Mesmo que o serviço esteja explicitamente permitindo o login de um dado usuário, se pam_access estiver sendo usado e este mesmo usuário estiver bloqueado no access.conf, o login não será permitido.
pam_limits
Este módulo é muito importante quando se tem usuários com shell em um servidor. Basicamente, ele configura limites para os recursos do sistema disponíveis para o usuário: uso de CPU, memória e outros que serão vistos a seguir. Note que estes limites são aplicados por processo, e não por usuário[2]. Este módulo entra apenas na categoria session e seu arquivo de configuração, /etc/security/limits.conf, contém vários detalhes. As entradas do arquivo de configuração do módulo pam_limits são da seguinte forma:
<domínio> <tipo> <item> <valor> |
- domínio:
-
Pode ser um nome de usuário, um nome de grupo (usando a sintaxe @grupo) ou um asterisco (*), indicando qualquer domínio.
- tipo:
-
Pode ter somente dois valores: hard e soft. Limites do tipo hard são aqueles definidos pelo superusuário e impostos pelo kernel do Linux. O usuário não pode aumentar estes limites. Por outro lado, limites do tipo soft são aqueles que o usuário pode alterar, desde que não ultrapasse o que foi definido como um limite hard. Pode-se pensar neste último tipo de limites como sendo valores padrão para o usuário, ou seja, ele começa com estes valores.
- item:
-
pode ser um dos seguintes:
-
core: tamanho máximo para arquivos core (KB).
-
data: tamanho máximo do segmento de dados de um processo na memória (KB).
-
fsize: tamanho máximo para arquivos que forem criados.
-
memlock: tamanho máximo de memória que um processo pode bloquear na memória física (KB).
-
nofile: quantidade máxima de arquivos abertos de cada vez.
-
rss: tamanho máximo de memória que um processo pode manter na memória física (KB).
-
stack: tamanho máximo da pilha (KB).
-
cpu: tempo máximo de uso de CPU (em minutos).
-
nproc: quantidade máxima de processos disponíveis para um único usuário.
-
as: limite para o espaço de endereçamento.
-
maxlogins: quantidade máxima de logins para este usuário.
-
priority: a prioridade com que os processos deste usuário serão executados.
-
- valor:
-
Aqui deve ser colocado o valor para o item da coluna anterior.
É importante notar que se existirem limites para um usuário e para o seu grupo, os limites para o usuário terão preferência sobre os limites especificados para o seu grupo. E, mais uma vez, não basta alterar o arquivo de configuração se o módulo não for usado. Este é um módulo da categoria session, e deve ser utilizado da seguinte forma:
session required /lib/security/pam_limits.so |
O módulo aceita dois parâmetros:
-
debug: aumenta a quantidade de mensagens que vão para o log do sistema;
-
conf=/caminho/para/arquivo.conf: indica um arquivo de configuração alternativo.
A seguir serão mostrados alguns exemplos. Número máximo de logins simultâneos para o grupo grupo1:
@grupo1 - maxlogins 1 |
Ultrapassando este limite, o usuário receberá uma mensagem na tela informando que excedeu o número máximo de logins e o log mostrará:
Mar 19 16:39:52 kepler pam_limits[14659]:Too many logins (max 1) \ |
Se o PAM estiver sendo utilizado, isto vale também para logins remotos. Por exemplo, vale direto para o telnet, pois ele usa o programa login. Para fazer valer para SSH também, basta acrescentar o módulo pam_limits ao /etc/pam.d/sshd.
# telnet localhost |
Número máximo de processos para o grupo grupo2:
@grupo2 - nproc 3 |
Exemplo:
kepler login: usuario |
Este recurso de se limitar o número de processos é bastante interessante, pois evita um fork bomb se usado em conjunto com os outros parâmetros, como tempo máximo de uso de CPU por processo e com os parâmetros relacionados ao uso de memória e também limitando o número de logins simultâneos.
Note que alguns processos possuem seu próprio controle do uso de recursos, como o Sendmail ou mesmo o Apache, e se recusam a criar mais sub-processos em conseqüência de certas condições de carga da máquina.
pam_time
O módulo pam_time pode ser usado para controlar o acesso a um serviço baseado no horário e dia da semana. A sintaxe para o uso do módulo é:
account required /lib/security/pam_time.so |
O seu arquivo de configuração padrão é /etc/security/time.conf e as entradas são no formato:
serviço;terminal;usuários;horários |
-
serviço: o nome do serviço, como, por exemplo, login ou sshd.
-
terminal: uma lista de terminais.
-
usuários: lista de usuários. Grupos não são suportados.
-
horários: lista de horários no formato DiaHorário. Para indicar os dias, deve-se usar a abreviação do dia da semana em inglês, além de outras abreviações úteis; veja a Tabela 7-2.
Tabela 7-2. Horários de Restrição de Login
|
Dia |
Valor a ser usado na lista de horários |
|---|---|
|
Segunda-feira |
Mo |
|
Terça-feira |
Tu |
|
Quarta-feira |
We |
|
Quinta-feira |
Th |
|
Sexta-feira |
Fr |
|
Sábado |
Sa |
|
Domingo |
Su |
|
Dias úteis |
Wk |
|
Fim-de-semana |
Wd |
|
Todos os dias |
Al |
Uma "lista", da forma como pode ser usada aqui, é uma seqüência de nomes e opcionalmente alguns caracteres especiais: ! (negação), * (curinga), & (AND) e | (OR).
Para especificar os horários, deve-se sempre utilizar o primeiro valor referente ao dia da semana e logo após a faixa de horários; por exemplo, Mo1800-0900 indica apenas a segunda-feira das 18h às 9 horas do dia seguinte, e Wk0900-1800 indica dias úteis (segunda a sexta) das 09 às 18 horas.
Para somente permitir o login no console nos dias úteis das 8 até às 18 horas, mas permitindo o login de root em qualquer horário, use:
login ; tty* ; !root ; Wk0800-1800 |
Uma observação importante: o processo de verificação do horário é feito apenas no início da sessão. Ou seja, não existe nenhum mecanismo que force a saída do usuário após o término do horário permitido de login. Por exemplo, aproveitando a regra acima, se um usuário se logar às 17h59 e não fizer logout, ele continuará na máquina mesmo após às 18 horas. Se ele sair, no entanto,não conseguirá entrar de novo pelo menos até às 8 horas do dia seguinte. Para contornar este problema, pode-se usar a variável de ambiente TMOUT[3] do bash. Esta variável especifica o tempo de inatividade máximo de uma sessão. Passando esse tempo, o logout é forçado.
Desabilitando Serviços Desnecessários
Os serviços normalmente habilitados no seu Conectiva Linux dependem do perfil utilizado na instalação do sistema. Portanto, após instalar o sistema você deve verificar quais deles realmente precisam estar habilitados. Existem, basicamente, dois tipos de serviços: aqueles que rodam no modo standalone e aqueles que rodam através do xinetd.
Serviços Standalone
Serviços que rodam no modo standalone são geralmente executados durante a inicialização do sistema, através dos chamados scripts de inicialização. O Apache e o LDAP são exemplos desses serviços.
Uma das ferramentas que podem ser utilizadas para configurar os serviços a serem executados é o Linuxconf. Para reiniciar, parar ou acionar serviços dirija-se ao menu Controle -> Painel de Controle -> Controle de atividades e serviços e seleciona o serviço desejado.
Outra ferramenta que pode ser utilizada é o ntsysv. Para instalá-lo, basta utilizar o apt-get (não esqueça de atualizar o arquivo de repositórios antes de instalar o pacote):
# apt-get install ntsysv |
-
ntsysv
Para a configuração dos serviços a serem executados, basta selecioná-los na janela do ntsysv. Para executá-lo, digite:
# /usr/sbin/ntsysv |
A Figura 7-2 ilustra a tela do programa ntsysv. Através desta tela você pode (e deve) desabilitar todos os serviços que não são utilizados. Para obter uma descrição de um serviço, selecione-o e pressione a tecla de função F1. Note que outros tipos de serviços são iniciados automaticamente, e não apenas serviços de rede. O gpm, por exemplo, é um serviço que adiciona suporte a mouse para aplicações que rodam no modo texto. Tome o cuidado de desabilitar apenas os serviços que não devem ser utilizados na máquina. Por exemplo, não desabilite o serviço httpd se for necessário rodar um servidor web na máquina.
O ntsysv configura apenas o nível de execução atual. Se você deseja configurar outros níveis de execução, estes níveis podem ser especificados na linha de comando, através da opção - -levels. É possível configurar vários níveis de execução simultaneamente. Executando o comando ntsysv - -levels 345, por exemplo, seriam configurados os níveis 3, 4 e 5 simultaneamente. Neste caso, se um serviço for marcado como habilitado, ele será habilitado em todos os níveis de execução especificados. De maneira análoga, ao desabilitar um serviço, o mesmo será desabilitado em todos os níveis de execução especificados.
Serviços Executados Através do xinetd
O xinetd (Extended Internet Services Daemon) é um daemon[4] geralmente executado na inicialização do sistema e que espera por conexões em alguns sockets internet específicos. Quando uma conexão é estabelecida em algum destes sockets, ele verifica a qual serviço o socket corresponde e invoca o programa capaz de servir a requisição em questão. Resumidamente, ele invoca daemons sob demanda, reduzindo a carga da máquina. Obviamente, este tempo necessário para invocar um daemon sob demanda pode ser prejudicial em serviços muito utilizados e é por isto que muitos serviços não podem ser executados através do inetd.
Nota: O xinetd trabalha de modo análogo ao inetd, possuindo somente arquivos de configuração diferentes. O inetd ainda continua na distribuição, podendo ser encontrado em um dos outros CDs do Conectiva Linux.
A configuração do xinetd reside no arquivo /etc/xinetd.conf e no diretório /etc/xinetd.d, embora o arquivo /etc/services também seja utilizado para mapear nomes de serviços para suas respectivas portas e protocolos. Estes arquivos podem ser alterados através de um editor de textos, ou então através do Linuxconf.
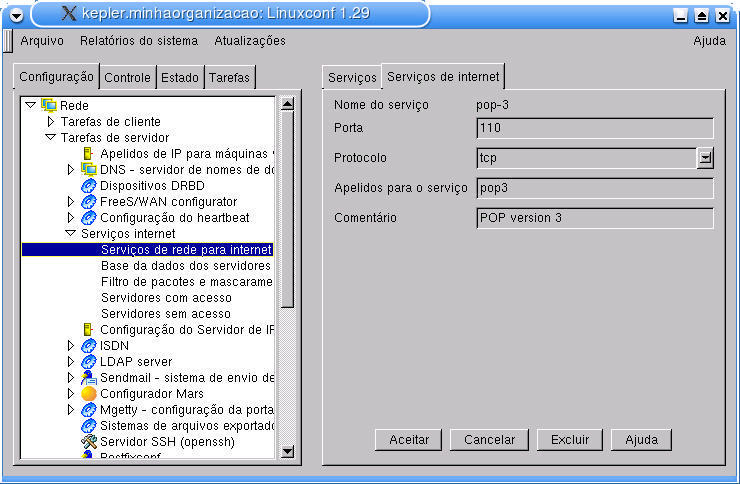
A configuração dos serviços e portas para o xinetd no Linuxconf é efetuada através da configuração de Configuração -> Rede -> Tarefas de servidor -> Serviços Internet. Esta configuração compreende a administração do arquivo /etc/services (opção Serviços de rede para Internet). Através desta opção, é possível adicionar, modificar ou remover o mapeamento do nome de um serviço para sua respectiva porta e protocolo. A Figura 7-3 ilustra a configuração do serviço chamado pop-3.
O arquivo /etc/xinetd.conf possui a configuração que será aplicada aos serviços contidos no diretório /etc/xinetd.d, e não é necessária nenhuma mudança em especial. Para informações mais detalhadas sobre as opções deste arquivo, dirija-se ao capítulo sobre o xinetd do Guia Entendendo o Conectiva Linux.
Um exemplo de serviço (echo) pode ser visto abaixo:
# default: off |
Pode-se notar que este serviço está desabilitado (disable = yes), e portanto, para desabilitar qualquer serviço, basta modificar esta linha e reinicializar o xinetd:
# service xinetd restart |
Como regra geral, mantenha desabilitados os serviços:
-
echo;
-
discard;
-
daytime;
-
chargen;
-
shell;
-
login;
-
exec;
-
talk (e similares);
-
tftp;
-
bootps;
-
finger (e similares);
-
systat;
-
netstat;
-
time.
Estes serviços dificilmente são necessários em sua máquina e possíveis invasores costumam utilizá-los como amostra do que está habilitado na máquina que pretendem invadir. Além destes, desabilite todos aqueles que não serão utilizados. Por exemplo, se não for necessário um servidor FTP na máquina, desabilite-o e, preferencialmente, desinstale do sistema o pacote correspondente.
Utilizando TCP_Wrappers
O pacote tcp_wrappers é utilizado para controlar o acesso a serviços. O xinetd já está configurado no Conectiva Linux para o uso do tcp_wrappers em todos os daemons possíveis e recomendados.
Os aplicativos necessários à utilização de tcp_wrappers já vêm instalados por padrão no Conectiva Linux. Você pode verificar procurando, na lista de pacotes instalados do Synaptic, pelo pacote tcp_wrappers.
Configurando tcp_wrappers
A configuração dos serviços com tcp_wrappers deve ser efetuada através dos arquivos /etc/hosts.allow e /etc/hosts.deny. Em /etc/hosts.deny são configuradas as regras para negar serviços a determinados clientes, ao mesmo tempo em que no arquivo /etc/hosts.allow configuram-se regras para permitir que determinados clientes tenham acesso a serviços.
Existem dezenas de possibilidades de configuração para o tcp_wrappers e você pode estudá-las em extensão através das páginas de manual hosts_access e hosts_options. Portanto, serão ilustrados apenas alguns casos interessantes do uso desta ferramenta.
As regras de controle de acesso, existentes nestes dois arquivos, têm o seguinte formato:
lista_de_daemons : lista_de_clientes [ : comando ]
- lista_de_daemons
-
Lista de um ou mais nomes de daemons como especificados no /etc/inetd.conf, ou curingas.
- lista_de_clientes
-
Lista de um ou mais endereços ou nomes de máquinas, padrões ou curingas utilizados para especificar quais clientes podem e quais não podem acessar o serviço.
- comando (opcional)
-
É possível executar um comando sempre que uma regra casa com um padrão e é utilizada. Veja exemplos a seguir.
Como citado anteriormente, curingas podem ser utilizados tanto na lista de daemons quanto na lista de clientes. Entre os existentes, pode-se destacar os seguintes:
- ALL
-
Significa todos os serviços ou todos os clientes, dependendo apenas do campo em que se encontra.
- LOCAL
-
Este curinga casa com qualquer nome de máquina que não contenha um caractere ponto ".", isto é, uma máquina local.
- PARANOID
-
Casa com qualquer nome de máquina que não case com seu endereço. Isto geralmente ocorre quando algum servidor DNS está mal configurado ou quando alguma máquina está tentando se passar por outra.
Na lista de clientes podem ser utilizados nomes ou endereços de máquinas, ou então padrões que especificam um conjunto de máquinas. Se a cadeia de caracteres que identifica um cliente inicia com um ponto ".", um nome de máquina irá casar com este padrão sempre que o final desse nome casar com o padrão especificado. Por exemplo, se fosse utilizada a cadeia de caracteres ".minhaorganizacao", o nome de máquina galileu.minhaorganizacao casaria com o padrão.
Similarmente, se a cadeia de caracteres termina com um ponto ".", um endereço de máquina irá casar com o padrão quando seus campos numéricos iniciais casarem com a cadeia de caracteres especificada. Para exemplificar, se fosse utilizada a cadeia de caracteres "192.168.220.", todas as máquinas que tenham um endereço IP que inicie com estes 3 conjuntos de números irão casar com o padrão (192.168.220.0 ao 192.168.220.255).
Além destes métodos, é possível identificar um cliente através do IP/máscara de rede. Você pode especificar, por exemplo, "192.168.220.0/255.255.255.128", e qualquer máquina com endereço IP entre 192.168.220.0 e 192.168.220.127 casaria com o padrão.
Uma boa política é fechar completamente o acesso de todos os serviços a quaisquer clientes, através do arquivo /etc/hosts.deny, e seletivamente liberar o acesso aos serviços necessários através do arquivo /etc/hosts.allow. No Exemplo 7-1, está descrita uma configuração que libera o acesso a FTP apenas ao domínio minhaorganizacao, o acesso ao servidor POP3 a qualquer máquina, todos os serviços para localhost e nega-se os demais serviços para qualquer máquina que seja.
Exemplo 7-1. Exemplo de Configuração do tcp_wrappers
Segue abaixo o arquivo /etc/hosts.deny:
ALL:ALL |
Arquivo /etc/hosts.allow:
ALL: localhost |
No Exemplo 7-2, considere o mesmo arquivo /etc/hosts.deny do exemplo anterior:
Exemplo 7-2. Configuração do tcp_wrappers menos restritiva
Arquivo /etc/hosts.allow:
ALL: localhost |
Neste último caso, máquinas da rede "200.234.123.0/255.255.255.0" e máquinas em que o endereço IP inicie por "200.248." também podem acessar o serviço FTP. Note que foi utilizado um operador novo para o serviço ipop3d: EXCEPT. Isto permitiu que o acesso a este serviço fosse liberado para todos, exceto para máquinas da rede "hackerboys.org".
O operador EXCEPT pode ser utilizado tanto na lista de clientes quanto na lista de serviços. Por exemplo, a linha:
ALL EXCEPT in.ftpd: ALL
no arquivo /etc/hosts.allow permite o acesso a todos os serviços, exceto o FTP, para qualquer máquina.
Todos os acessos, bem-sucedidos ou não, são registrados através do syslog. No Conectiva Linux estas informações são registradas no arquivo /var/log/secure. É recomendado que este arquivo seja periodicamente analisado à procura de tentativas de invasão.
Vários outros exemplos de configuração estão descritos nas páginas de manual citadas anteriormente (hosts_access e hosts_options).
Testando a Configuração
Negue certos serviços para uma máquina de sua rede (como por exemplo o serviço telnet) e após reinicializar o xinetd, procure fazer acessos da máquina onde o serviço foi negado.
Verificando a Integridade do Sistema
Uma das primeiras ações de um invasor costuma ser substituir arquivos e programas do sistema com o intuito de mascarar sua visita atual e, principalmente, facilitar as visitas futuras. Portanto, se houver a possibilidade de verificar a integridade de arquivos do sistema, haverá uma grande possibilidade de detectar uma invasão. E o melhor é que este recurso permite que se saiba quais arquivos foram modificados, possibilitando que o administrador decida entre reinstalar o sistema ou apenas substituir o arquivos alterados pelos originais.
Após perceber que a máquina foi invadida, o administrador costuma analisar o sistema utilizando programas como ps, ls, netstat e who. Ocorre que estes programas são os primeiros a serem substituídos, ocultando, assim, a invasão e o invasor propriamente dito. Mesmo que se tenha a informação de data e tamanho dos arquivos originais, estas informações, sozinhas, não podem ser utilizadas como parâmetro, pois podem ser facilmente modificadas. Contudo, se além destas informações estiver disponível algo como o checksum MD5 dos arquivos, torna-se bem mais simples encontrar arquivos indevidamente modificados.
O AIDE (Advanced Intrusion Detection Environment) é um programa que tem justamente a finalidade de verificar a integridade dos arquivos do sistema. Ele constrói uma base de dados com várias informações dos arquivos especificados em seu arquivo de configuração. Esta base de dados pode conter vários atributos dos arquivos, como:
-
permissões;
-
número do inode;
-
dono;
-
grupo;
-
tamanho;
-
data e hora de criação, último acesso e última modificação.
Além disso, o AIDE também pode gerar e armazenar nesta base de dados o checksum criptográfico dos arquivos, utilizando um, ou uma combinação dos seguintes algoritmos: md5, sha1, rmd160 e tiger.
O procedimento recomendado é que você crie esta base de dados em um sistema recém-instalado, antes de conectá-lo a uma rede. Esta base de dados será a fotografia do sistema em seu estado normal e o parâmetro a ser utilizado para medir alterações no sistema de arquivos. Obviamente, sempre que você modificar o seu sistema, como por exemplo através da instalação, atualização ou remoção de programas, uma nova base de dados deve ser gerada. Esta nova base de dados é que deve ser utilizada como parâmetro. A base de dados deve conter informações sobre binários, bibliotecas e arquivos de cabeçalhos importantes do sistema, já que estes não costumam ser alterados durante o uso normal do sistema. Informações sobre arquivos de log, filas de correio eletrônico e de impressão, diretórios temporários e de usuários não devem ser armazenados na base de dados, já que são arquivos e diretórios freqüentemente alterados.
Instalando o AIDE
Para instalar o AIDE, utilize o apt-get, digitando o seguinte comando em um terminal:
# apt-get install aide |
Configuração do AIDE
A configuração do AIDE reside no arquivo /etc/aide.conf. Este arquivo tem três tipos de linhas:
linhas de configuração: utilizadas para definir parâmetros de configuração do AIDE.
linhas de seleção: utilizadas para indicar quais arquivos terão suas informações adicionados à base de dados.
linhas de macro: utilizadas para definir variáveis no arquivo de configuração.
Apenas as linhas de seleção são essenciais ao funcionamento do AIDE. Existem, por sua vez, três tipos de linhas de seleção. Estas linhas são interpretadas como expressões regulares. Linhas que começam com uma barra "/" indicam que os arquivos que casarem com o padrão terão suas informações adicionadas ao banco de dados. Se a linha iniciar com um ponto de exclamação "!", ocorre o contrário: os arquivos que casam com o padrão são desconsiderados. Linhas iniciadas por um sinal de igualdade "=" informam ao AIDE que somente arquivos que sejam exatamente iguais ao padrão devem ser considerados.
Através das linhas de configuração é possível definir alguns parâmetros de funcionamento do AIDE. Estas linhas têm o formato parâmetro=valor. Os parâmetros de configuração estão descritos a seguir:
- database
-
A URL do arquivo de banco de dados de onde as informações são lidas. Pode haver somente uma linha destas. Se houver mais de uma, apenas a primeira será considerada. O valor padrão é ./aide.db.
- database_out
-
A URL do arquivo de banco de dados onde são escritas as informações. Assim como database, deve haver apenas uma linha destas. No caso de haver várias, somente a primeira ocorrência será considerada. O valor padrão é ./aide.db.new.
- report_url
-
A URL onde a saída do comando é escrita. Se existirem várias instâncias deste parâmetro, a saída será escrita em todas as URLs. Se você não definir este parâmetro, a saída será enviada para a saída padrão (stdout).
- verbose
-
Define o nível de mensagens que é enviado à saída. Este valor pode estar na faixa entre 0 e 255 (inclusive) e somente a primeira ocorrência deste parâmetro será considerada. É possível sobrescrever este valor através das opções - -version ou -V na linha de comando.
- gzip_dbout
-
Informa se o banco de dados deve ser compactado ou não. Valores válidos para esta opção são yes, true, no e false.
- Definições de grupos
-
Se o parâmetro não for nenhum dos anteriores então ele é considerado uma definição de grupo. Embora existam alguns grupos predefinidos que informam ao AIDE quais as informações do arquivo que devem ser armazenadas na base de dados, você pode criar suas próprias definições. A Tabela 7-3 mostra os grupos predefinidos.
Tabela 7-3. Grupos Predefinidos
p permissões i inode n número de links u dono g grupo s tamanho m data e hora da última modificação a data e hora do último acesso c data e hora da criação do arquivo S verifica o aumento do tamanho do arquivo md5 checksum md5 sha1 checksum sha1 rmd160 checksum rmd160 tiger checksum tiger R p+i+n+u+g+s+m+c+md5 L p+i+n+u+g E grupo vazio > arquivo de log (aumenta o tamanho) - p+u+g+i+n+S
Você poderia definir um grupo que verifica apenas o dono e o grupo do arquivo, da seguinte maneira:
trivial=u+g
As linhas de macro podem ser utilizadas para definir variáveis e tomar decisões baseadas no valor destas. Informações detalhadas podem ser encontradas na página de manual do arquivo de configuração (man aide.conf).
O termo URL, utilizado na configuração dos parâmetros database, database_out e report_url, pode assumir um dos seguintes valores:
stdout: a saída é enviada para a saída padrão.
stderr: a saída é enviada para a saída padrão de erros.
stdin: a entrada é lida da entrada padrão.
file:/arquivo: a entrada é lida de arquivo ou a saída é escrita em arquivo.
fd:número: a entrada é lida do filedescriptor número ou a saída é escrita no filedescriptor número.
Note que URLs de entrada não podem ser utilizadas como saídas e vice-versa.
O Exemplo 7-3 ilustra uma configuração básica para o AIDE.
Exemplo 7-3. Arquivo de Configuração do AIDE
# Localização da base de dados |
O ideal é ignorar diretórios que são modificados com muita freqüência, a não ser que você goste de logs gigantescos. É um procedimento recomendado excluir diretórios temporários, filas de impressão, diretórios de logs e quaisquer outras áreas freqüentemente modificadas. Por outro lado, é recomendado que sejam incluídos todos os binários, bibliotecas e arquivos de cabeçalhos do sistema. Muitas vezes é interessante incluir diretórios que você não costuma observar, como o /dev/ e o /usr/man.
| Atenção |
|
Se sua idéia é referir-se a um único arquivo, você deve colocar um $ no final da expressão regular. Com isto, o padrão casará apenas com o nome exato do arquivo, desconsiderando arquivos que tenham o início do nome similar. |
O pacote do AIDE que acompanha o Conectiva Linux tem um arquivo de configuração padrão funcional, mas nada o impede de modificá-lo para refletir suas necessidades.
Utilização do AIDE
Como o arquivo de configuração padrão deverá servir para a maioria dos casos, para gerar o banco de dados basta executar os comandos:
# /usr/bin/aide -i |
Após esta operação, você deve executar o comando:
# /usr/bin/aide-md5 [dispositivo de boot] |
O parâmetro [dispositivo de boot] é opcional, e corresponde ao dispositivo de armazenamento utilizado para inicialização do sistema (/dev/hda, por exemplo).
O aide-md5 foi desenvolvido pela Conectiva e supre a falta de assinatura do banco de dados do AIDE. Ele informa os somatórios MD5 de alguns componentes críticos ao funcionamento do AIDE, inclusive do próprio banco de dados recém-gerado. Você deve tomar nota desses somatórios para verificação posterior.
Se o dispositivo de boot for informado ao aide-md5, o MD5 do setor de boot também será calculado, portanto é interessante informar esse parâmetro.
Testando a Configuração
Para verificar a integridade do sistema, execute o próprio AIDE, desta forma:
# /usr/bin/aide -C |
Os arquivos que sofreram qualquer mudança, seja no tamanho, conteúdo, permissões ou data de criação, serão listados.
É provável que, na maioria das vezes que o AIDE apontar diferenças em arquivos, elas tenham sido provocadas por atos legítimos, por exemplo, atualização de pacotes ou intervenção do administrador do sistema. Nesses casos, o administrador deve, após uma conferência, reconstruir o banco de dados.
Para verificar a integridade do próprio AIDE, deve-se novamente utilizar o programa aide-md5, mas desta vez, de uma mídia removível, como, por exemplo, de um disquete:
# /mnt/floppy/aide-md5 /dev/hda |
Se algum dos códigos MD5 não bater com aqueles gerados anteriormente, o(s) respectivo(s) componente(s) pode(m) estar comprometido(s), e isto é um problema muito sério.
Obviamente que, se você alterou as configurações do AIDE, regerou o banco de dados ou atualizou o kernel, os códigos serão diferentes. Logo após efetuar quaisquer destas alterações, você deve executar novamente o aide-md5 e anotar os códigos.
| Atenção |
|
É altamente recomendável copiar o aide-md5 para um meio removível, protegido contra gravação, e uma vez que o sistema tenha entrado em produção, deve-se executá-lo sempre a partir daquele meio, eventualmente removendo o aide-md5 original do disco rígido. Pois, se você fizer uso do aide-md5 do disco rígido, e este for comprometido, o invasor pode forjar somatórios MD5 falsamente perfeitos. |
Bind-Chroot
O bind-chroot é uma versão do bind padrão modificada para executá-lo de modo "enjaulado"[5] dentro de um diretório, de maneira que ele não tenha acesso aos diretórios do sistema. Essa característica garante que, caso o bind-chroot seja atacado e forneça acesso à máquina, o invasor não terá acesso aos diretórios externos àquele utilizado pelo bind-chroot[6].
Características do Bind-chroot
A seguir serão vistas algumas das vantagens de se "enjaular" o bind num diretório específico:
-
Caso um invasor consiga, durante um ataque, acesso à sua máquina, ele não poderá navegar na estrutura de diretórios acima do diretório no qual o bind foi "enjaulado".
-
Dentro do diretório onde o bind estiver "enjaulado" existirão apenas os arquivos necessários para a utilização do bind, não deixando brechas para a execução de, por exemplo, um shell (/bin/sh) caso sua máquina seja atacada.
Para utilizar o bind-chroot é preciso criar uma nova estrutura de diretórios semelhante à estrutura do diretório raiz (/) e duplicar alguns arquivos[7] existentes no seu disco rígido para que ele possa executar "enjaulado". A instalação do pacote bind-chroot já cria todos os diretórios e arquivos necessários para a utilização dele.
Nota: Um detalhe importante é que, caso haja uma atualização dos arquivos das bibliotecas[8] que o bind-chroot utiliza, o administrador do sistema deverá lembrar de atualizar os arquivos dentro do diretório onde ele está "enjaulado".
Pré-requisitos
Para utilizar o bind-chroot, você irá precisar ter o bind instalado e configurado.
Nota: Um detalhe que muitas vezes passa despercebido é que quando você instala o bind-chroot você deve alterar o arquivo /etc/sysconfig/named, modificando para yes o parâmetro CHROOT.
Instalação
Para instalar o bind-chroot, execute o Synaptic e selecione o seguinte pacote para a instalação:
-
bind-chroot
É possível também instalar o bind-chroot utilizando o apt-get:
# apt-get install bind-chroot |
Configuração do Bind-chroot
A configuração do bind-chroot é idêntica à configuração do bind, já vista no Capítulo 1. A única diferença entre as configurações do bind e do bind-chroot é a localização do arquivo de configuração. O arquivo de configuração do bind-chroot está localizado em /var/named/etc/named.conf em vez de estar no /etc/named.conf, que é o local padrão do arquivo de configuração do bind.
Observe que toda a estrutura de arquivos do bind-chroot é idêntica à utilizada pelo bind, porém relativa à /var/named/, que é o diretório raiz para o bind-chroot.
Testando a Configuração
Para testar se o bind-chroot está executando "enjaulado", no terminal digite:
# ps auxwww | grep named |
O comando acima deverá mostrar uma saída semelhante a esta:
named 1805 0.0 2.7 11652 3460 ? S Mar05 0:00 named -u named -t \ |
Observe nas linhas acima a opção -t /var/named na linha de execução do bind; essa opção indica que o bind será executado "enjaulado" no diretório /var/named/. Outra maneira de verificar se o bind está rodando "enjaulado" é listar o conteúdo do diretório /proc/pid/, onde pid é o número do processo do bind que está executando. Tomando como exemplo o processo 1805, veja a saída do comando a seguir:
# l /proc/1805 |
Observe a quarta linha de baixo para cima, onde está indicada a opção root. Note que esse arquivo é um link para /var/named/, indicando que o diretório raiz desse processo é /var/named/. Dessa maneira, verifica-se que o bind está executando "enjaulado".
Firewall Através de Filtro de Pacotes
Um firewall é um sistema que isola redes distintas e permite que se controle o tráfego entre elas. Um exemplo típico onde a utilização de um firewall é recomendada é na conexão de uma rede local à Internet. Embora o conceito de firewall seja bastante amplo e possa envolver servidores proxy, analisadores de logs e filtros de pacotes, entre outras características, nesta seção será visto somente o filtro de pacotes fornecido pelo kernel do Linux.
O kernel do Linux conta com um filtro de pacotes bastante funcional, que permite que sua máquina descarte ou aceite pacotes IP, baseando-se na origem, no destino e na interface pela qual o pacote foi recebido. A origem e o destino de um pacote são caracterizados por um endereço IP, um número de porta e pelo protocolo.
Todo o tráfego através de uma rede é enviado no formato de pacotes. O início de cada pacote informa para onde ele está indo, de onde veio e o tipo do pacote, entre outros detalhes. A parte inicial deste pacote é chamada cabeçalho. O restante do pacote, contendo a informação propriamente dita, costuma ser chamado de corpo do pacote.
Um filtro de pacotes analisa o cabeçalho dos pacotes que passam pela máquina e decide o que fazer com o pacote inteiro. Possíveis ações a serem tomadas em relação ao pacote são:
aceitar: o pacote pode seguir até seu destino.
rejeitar: o pacote será descartado, como se a máquina jamais o tivesse recebido.
bloquear: o pacote será descartado, mas a origem do pacote será informada de que esta ação foi tomada.
O filtro de pacotes do kernel é controlado por regras de firewall, as quais podem ser divididas em quatro categorias: a cadeia de entrada (input chain), a cadeia de saída (output chain), a cadeia de reenvio (forward chain) e cadeias definidas pelo usuário (user defined chain). Para cada uma destas cadeias é mantida uma tabela de regras separada.
Uma regra de firewall especifica os critérios de análise de um pacote e o seu alvo (target). Se o pacote não casa com o padrão especificado pela regra, a regra seguinte da cadeia é analisada. Se desta vez o pacote casar com o padrão, a regra seguinte é definida pelo alvo, que pode ser o nome de uma cadeia definida pelo usuário, ou um dos seguintes valores especiais:
- ACCEPT
-
Significa que o filtro de pacotes deve deixar o pacote passar.
- DROP
-
Significa que o filtro de pacotes deve impedir que o pacote siga adiante.
- REJECT
-
Assim como DROP, significa que o pacote não deve seguir adiante, mas uma mensagem ICMP é enviada ao sistema originador do pacote, avisando-o de que o pacote foi rejeitado. Note que DENY e REJECT têm o mesmo significado para pacotes ICMP.
- MASQUERADE
-
Este alvo somente é válido para a cadeia de reenvio e para cadeias definidas pelo usuário, e somente pode ser utilizado quando o kernel é compilado com suporte a IP Masquerade. Neste caso, pacotes serão mascarados como se eles tivessem sido originados pela máquina local.
- REDIRECT
-
Este alvo somente é válido para a cadeia de entrada e para cadeias definidas pelo usuário e somente pode ser utilizado se o kernel foi compilado com a opção de Transparent proxy. Com isto, pacotes serão redirecionados para um socket local, mesmo que eles tenham sido enviados para uma máquina remota (veja o Capítulo 6 para mais detalhes). Obviamente isto só faz sentido se a máquina local é utilizada como gateway para outras máquinas. Se a porta especificada para redirecionamento é "0", que é o valor padrão, a porta de destino dos pacotes será utilizada como porta de redirecionamento. Se for especificada uma outra porta qualquer, esta será utilizada, independentemente daquela especificada nos pacotes.
- RETURN
-
Se a regra contendo o alvo RETURN foi chamada por uma outra regra, a regra seguinte da cadeia que a chamou é analisada. Caso ela não tenha sido chamada por outra regra, a política padrão da cadeia é utilizada para definir o destino do pacote.
Configurando o firewall utilizando Iptables
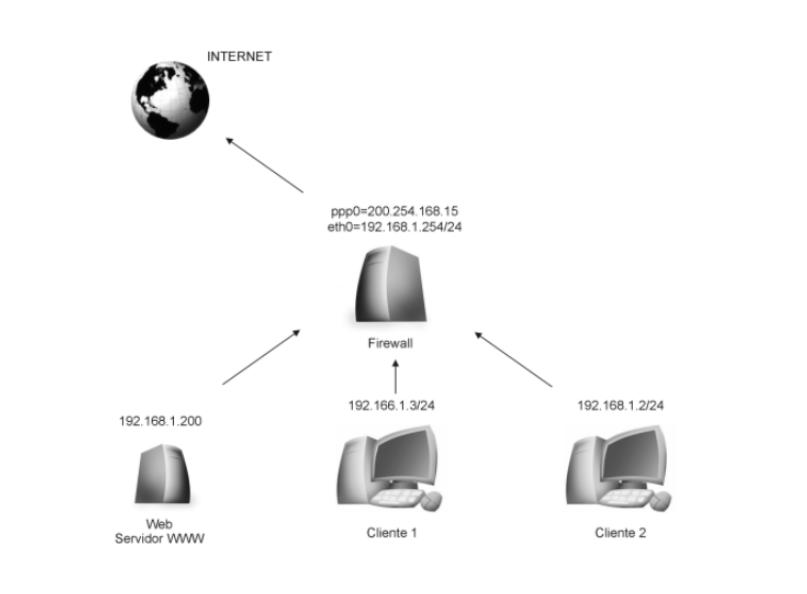
Nesta seção será visto como configurar o firewall utilizando o netfilter. Como o Linuxconf ainda não suporta o Iptables, deve-se efetuar as configurações manualmente digitando os comandos diretamente num terminal. Nesta seção será permitido que as máquinas internas acessem diretamente a Internet. O servidor Web será uma máquina interna com um número IP reservado. Veja a Figura 7-4.
Dica: Para entender melhor os conceitos do netfilter, leia a seção Netfilter Capítulo 6, onde esses conceitos são explicados com mais detalhes.
Os recursos disponibilizados pelo netfilter são manipulados através do comando iptables. Como a criação de regras através do netfilter é dinâmica, assim como o ipchains, seu conteúdo é perdido quando a máquina é reinicializada. Quando utiliza-se o Linuxconf para efetuar essas configurações, as regras são salvas num arquivo interno. Esse é um dos motivos pelos quais deve-se criar um script de inicialização para que, após configuradas as regras de utilização, elas sejam executadas a cada inicialização.
Antes da criação de scripts e definição de quais serão as regras a serem utilizadas, será mostrada um pouco da sintaxe utilizada pelo comando iptables no tratamento de ganchos pré-existentes[9]. A sintaxe mais utilizada do comando iptables é a seguinte:
# iptables [X] [cadeia] [índice ou especificação_da_regra] [opções] |
onde [X] pode ser:
-
-A: adicionar uma nova regra a uma cadeia.
-
-I: inserir uma nova regra numa posição em uma cadeia.
-
-R: substitui uma regra em uma posição da cadeia.
-
-D: apaga uma regra em uma posição da cadeia.
-
-D: apaga a primeira regra que casa com uma cadeia.
Basicamente, serão utilizadas as opções para adicionar (-A) e apagar (-D). As outras (-I para inserir e -R para substituir) são simplesmente extensões desses conceitos. Cada regra especifica um conjunto de condições que o pacote precisa satisfazer, e dependendo do que ele satisfizer, ele será direcionado para um destino ou para outro.
| Atenção |
|
É possível que, ao adicionar uma regra errada, sua máquina pare de funcionar corretamente. Neste caso, utilize o comando iptables -F, para que todas as regras do filtro de pacotes sejam desativadas. Porém, caso a política padrão esteja como DROP ou REJECT você precisará utilizar o comando iptables -P INPUT ACCEPT e a seguir iptables -P OUTPUT ACCEPT para redefinir a política padrão utilizada. Caso queira saber quais regras estão ativas, você pode usar o comando iptables -L . |
Pré-requisitos
Para poder utilizar o comando iptables você deverá ter o pacote iptables instalado no seu sistema e também o módulo ip_tables.o carregado.
Para carregar o módulo ip_tables execute o seguinte comando:
# modprobe ip_tables |
Instalação
Para instalar o iptables, selecione o seguinte pacote através do Synaptic:
-
iptables
É possível instalar o iptables utilizando o apt-get, digitando o seguinte comando em um terminal:
# apt-get install iptables |
Configurando as regras para o firewall
Como foi visto anteriormente (Capítulo 6), a política padrão da cadeia de entrada deveria ser definida como DROP, negando qualquer acesso à rede. A sintaxe utilizada pelo iptables para efetuar essa ação é:
# iptables -t filter -P INPUT DROP |
Deve-se permitir o acesso a um servidor web que escuta na porta 80 de uma máquina interna que possui o IP 192.168.1.200; porém, antes deve-se permitir todo e qualquer tráfego na interface lo (que é a interface de loopback), para que a comunicação inter-processos possa funcionar. É necessário, então, executar o seguinte comando:
# iptables -t filter -A INPUT -j ACCEPT -i lo |
Antes ainda do tráfego ser liberado para o servidor Web, precisa-se fazer com que o firewall permita que os pacotes pertencentes às conexões já estabelecidas e os pacotes relacionados a essas conexões possam passar pelo firewall. Para isso, são necessários os seguintes comandos:
# iptables -t filter -A FORWARD -j ACCEPT -m state --state |
Agora que realmente será liberado o acesso à porta 80 do servidor Web, utilizando o comando:
# iptables -t filter -A FORWARD -j ACCEPT -m state NEW -p tcp \ |
Caso deseje liberar ainda mais um tipo de acesso, pode-se liberar o acesso à requisições[10] IDENT, utilizadas pelo protocolo de autenticação (auth), o qual pode ser utilizado por servidores SMTP e alguns servidores FTP. Para esse acesso ser liberado, basta executar o comando:
# iptables -t filter -A FORWARD -j ACCEPT -m state NEW -p tcp \ |
Agora, basta criar uma regra que irá rejeitar todos os pacotes que não casarem com as regras anteriores:
# iptables -t filter -A FORWARD -j REJECT |
Após configurar o firewall, falta apenas configurar o mascaramento na interface de saída:
# iptables -t nat -A POSTROUTING -j MASQUERADE -o ppp0 |
Neste exemplo, está sendo configurado o mascaramento dos pacotes com destino ao servidor web. Todos os pacotes que vierem da interface ppp0 que tiverem com o protocolo tcp e forem destinados à porta 80 são destinados para a máquina interna:
# iptables -t nat -A PREROUTING -j DNAT - -to-dest 192.168.1.200 \ |
A configuração do firewall foi finalizada. Porém, lembre-se de que estas regras desaparecerão assim que a máquina for reinicializada. Para evitar que isso ocorra, deve-se criar um script que irá executar junto com a inicialização da máquina, garantindo que as regras estejam funcionando.
Crie no diretório /etc/init.d/ um arquivo chamado iptables com o seguinte conteúdo:
#! /bin/sh |
Este script, além de inserir as regras necessárias para o firewall, carrega também os módulos do kernel necessários para este serviço.
Como você pode notar, esse script é muito semelhante ao utilizado anteriormente no Capítulo 6; a sugestão é unificar os dois scripts em um só para um melhor gerenciamento das regras utilizadas, considerando que, a única diferença nos dois scripts mencionados são as regras utilizadas.
Detectando Incidentes de Segurança
NIDS (Network Intrusion Detection System ou Sistema de Detecção de Intrusão de Rede) é um sistema que tem por objetivo principal a detecção de intrusos. Além disso, são sistemas que:
-
Analisam tráfego de rede;
-
Procuram por assinaturas de ataques;
-
Fazem o registro dos ataques e opcionalmente avisam um operador (realtime);
-
Trabalham com sensores; vários pontos da rede podem ser monitorados.
Nessa seção serão mostradas duas ferramentas presentes no Conectiva Linux que estão relacionadas com NIDS: Snort e ACID.
Características do Snort
O Snort é um aplicativo NIDS utilizado para detectar incidentes de segurança na sua rede. Ele pode analisar protocolos, procurar/casar conteúdos de pacotes, pode ser utilizado para detectar vários tipos de ataque, como, por exemplo, buffer overflow, portscan, ataques CGI e muitos outros. O Snort utiliza uma linguagem de regras muito flexível para descrever o tráfego que ele deve analisar ou deixar passar, e também um mecanismo de detecção que utiliza uma arquitetura modular de plugins, que registram os ataques de diversas maneiras. Veja alguns deles:
-
SQL (MySQL, PostgreSQL, Oracle, unixOdbc);
-
arquivo no formato tcpdump (binário);
-
arquivo texto;
-
XML;
-
syslog;
-
SMB (Winpopup).
O Snort pode ser considerado um sensor, podendo monitorar diferentes pontos da rede ao mesmo tempo.
A seguir, veja algumas das funcionalidades do Snort:
-
Normalizar requisições HTTP;
-
Detectar ataques do tipo Unicode;
-
Detectar portscan (por taxa e por flags);
-
Remontar os segmentos TCP;
-
Ativar regras dinamicamente (regras podem ser ativadas por outras regras).
Será visto aqui como instalar e configurar as opções básicas do Snort, utilizando-o em conjunto com o ACID[11], que é uma ferramenta utilizada para analisar os logs de incidentes do Snort, armazenados em um banco de dados.
Pré-requisitos
Para utilizar o Snort você precisa ter sua rede instalada e configurada. Será instalado, neste exemplo, Snort com suporte ao banco de dados MySQL, para ser possível utilizar o Snort juntamente com o ACID.
Deve-se também ter o Apache habilitado e configurado para trabalhar com PHP na máquina onde será configurado o ACID.
Instalação
Para instalar o Snort e o ACID, selecione os seguintes pacotes no Synaptic:
-
snort
-
MySQL
-
php4-mysql
-
acid
É possível instalar o Snort utilizando o apt-get, digitando os seguintes comandos em um terminal:
# apt-get install snort |
Nota: A instalação do Snort neste manual será feita em localhost apenas a título de exemplo. Na Figura 7-5 pode-se ver um exemplo de instalação distribuída em três máquinas diferentes; uma possui o Snort instalado, a outra possui o banco de dados (MySQL) e a terceira executa o Acid.
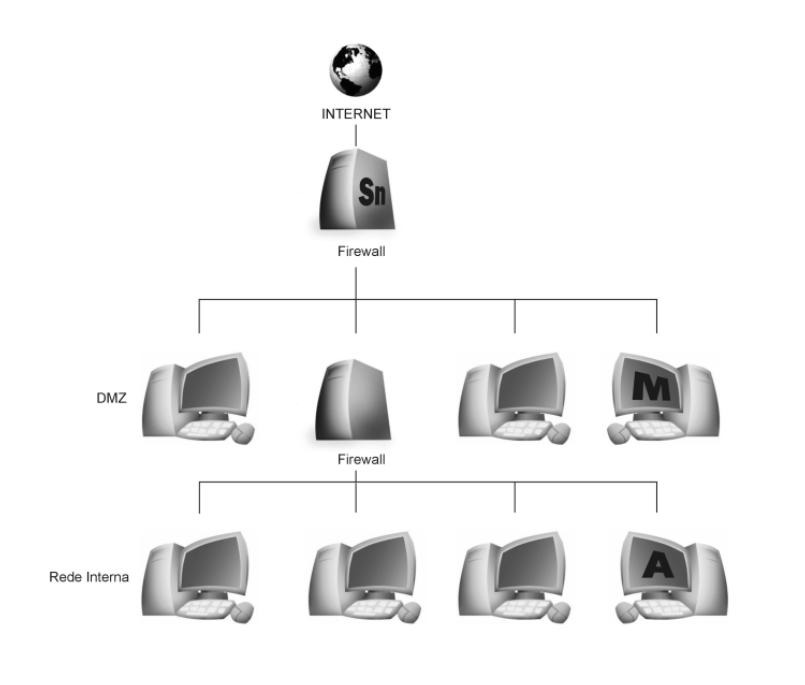
Configuração do Snort
Inicialmente é preciso configurar o banco de dados que será utilizado para o Snort registrar as ocorrências detectadas. Aqui será utilizado o MySQL, instalado no passo anterior. Para iniciar a configuração do MySQL execute o seguinte comando num terminal:
# /usr/sbin/mysql_createdb |
| Atenção |
|
Cuidado com a execução do comando a seguir. Execute-o somente se o MySQL nunca tiver sido utilizado antes, caso contrário você poderá perder seus dados. |
A seguir, o comando pedirá a senha do usuário root do MySQL; note que essa senha não é a senha do superusuário do seu sistema e sim do usuário root do banco de dados.
Agora que já foi definida a senha do usuário root, o serviço MySQL deve ser iniciado. Continue no terminal e digite:
# service mysql start |
Surgirá então uma mensagem indicando que o daemon do banco de dados foi iniciado.
O próximo passo é criar a base de dados na qual o Snort irá armazenar as ocorrências. Veja a seguir quais comandos utilizar.
# mysql -u root -p |
Na primeira linha de comando informa-se ao MySQL que deve-se iniciá-lo como usuário root e que ele deve pedir a senha do usuário. Na segunda e terceira linha cria-se a base de dados e o usuário que o Snort irá utilizar para registrar as ocorrências. Observe que o usuário snort não tem permissão de apagar nada, e nem precisa. A única operação que o Snort irá executar será inserir incidências na base de dados.
Na quarta linha, é criado o usuário acid com permissão de inserir, selecionar, apagar, atualizar e criar tabelas na base de dados. A permissão de criação é dada para o usuário acid somente enquanto não instala-se e configura-se esse aplicativo. Assim que a configuração do ACID estiver terminada, essa permissão deve ser retirada, pois abre uma brecha potencial na segurança.
Criada a base de dados e os usuários necessários, deve-se ir até o diretório /usr/share/doc/snort-versão/; lá está contido um script para criar as tabelas e demais estruturas que o Snort irá utilizar. Estando nesse diretório, execute o seguinte comando:
# mysql -u root -p snort < create_mysql |
O comando irá informar ao MySQLpara, como usuário root (do MySQL), executar na base de dados snort os comandos que estão no arquivo create_mysql. Você deverá informar a senha do usuário root do banco de dados para que o comando seja bem-sucedido. A seguir, execute o seguinte comando[12]:
# bzcat snortdb-extra.bz2 | mysql -u root -p snort |
Esse comando irá terminar de criar as estruturas necessárias para o Snort.
Terminada a criação da estrutura da base de dados necessária para a utilização do Snort, deve-se agora editar o arquivo de configuração que fica em /etc/snort/snort.conf, modificando os valores de acordo com a necessidade.
Edite o arquivo de configuração do Snort[13] e verifique as seguintes linhas:
#var HOME_NET $eth0_ADDRESS |
Em HOME_NET você pode especificar uma máquina, interface ou rede na qual o Snort irá "escutar", ou ainda especificar uma lista dos itens acima mencionados, como especificado no exemplo. Em EXTERNAL_NET você irá configurar o que o Snort deve considerar como sendo uma rede externa; no exemplo, o parâmetro any indica qualquer rede. A terceira variável desse primeiro passo (DNS_SERVERS) é especificada para que o Snort não considere as tentativas de acesso provenientes do servidor DNS como sendo tentativas de portscan. Seguindo mais para o final do arquivo de configuração pode-se verificar o seguinte trecho:
# database: log to a variety of databases |
Observe que a linha output database foi descomentada; ela refere-se ao banco de dados que é utilizado (MySQL). Foi inserido ao final da linha o parâmetro password=senha123, que indica ao Snort qual senha utilizar para efetuar o login no banco de dados.
Ao final do arquivo de configuração do Snort, são incluídos os arquivos que contêm as regras de filtragem que ele irá utilizar. O exemplo a seguir ilustra alguns arquivos de regras que podem ser incluídos:
include $RULE_PATH/bad-traffic.rules |
$RULE_PATH é a variável, definida neste mesmo arquivo, que contém o caminho para os arquivos de regras.
Cada arquivo desses contém regras e assinaturas específicas para reconhecer um tipo de ataque. Você pode encontrar mais arquivos com regras e assinaturas em: WhiteHats e no site do Snort .
O último passo para a configuração do Snort é editar o arquivo /etc/sysconfig/snort. A seguir são mostradas as opções a serem configuradas:
-
INTERFACE=eth0
-
AUTO=no
-
ACTIVATE=no
A variável INTERFACE indica em qual interface o Snort irá escutar[14], a variável AUTO=no indica que o Snort deverá pegar o endereço IP fornecido no arquivo de configuração; caso seja especificada essa opção como yes, o Snort irá pegar o valor IP diretamente da interface especificada, ignorando o valor presente no arquivo de configuração.
A variável ACTIVATE indica se o Snort deverá ser executado sempre que a interface "subir", pois quando a interface "cai", o Snort"cai" junto.
Inicie o serviço do Snort digitando o seguinte comando:
# service snort start |
Para verificar se o Snort está em execução, digite:
# service snort status |
Para configurar o ACID, deve-se primeiramente fazer com que o servidor web possua suporte ao PHP4, para que seja possível executar o ACID (consulte o Capítulo 3).
Em seguida, inicie o seu servidor web, pois o ACID será executado localmente.
# service http start |
A seguir, edite o arquivo /srv/www/default/html/acid/config/acid_conf.php, que contém as configurações do ACID. Você precisa modificar apenas as seguintes variáveis:
$alert_dbname = "snort"; |
A variável $alert_dbname indica o nome da base de dados a ser utilizada, as variáveis a seguir indicam: máquina onde se localiza a base de dados[15], porta, nome do usuário que o ACID irá utilizar para efetuar o login na base de dados e a senha a ser utilizada.
O resto da configuração do ACID se faz através do navegador. Inicie um navegador e digite o endereço local ; deverá surgir a janela mostrada na Figura 7-6.

Utilize o link Setup page para iniciar a configuração da base de dados. Na próxima página você verá um botão chamado CREATE ACID AG; clique nesse botão. A próxima página mostrará as mensagens de criação das bases de dados:
Sucessfully created `acid_ag` |
A próxima janela informa o estado do processo de criação das tabelas e índices e conduz à pagina principal do ACID, indicando que a sua configuração já foi finalizada e está pronto para ser utilizado.
Falta apenas retirar a permissão de criação de tabelas do usuário acid da base de dados. Voltando ao terminal modo texto, digite:
# mysql -u root -p |
Testando a Configuração
Para testar a configuração, será simulado um ataque. Inicialmente, verifique se o Snort está executando na máquina a ser atacada:
# service snort status |
Com ele executando, efetue o login como usuário root em outra máquina da sua rede e utilize o comando nmap ip_da_maquina_a_ser_atacada. Caso não tenha o nmap instalado, instale-o utilizando o Synaptic, ou através do apt-get, com os comandos a seguir.
# apt-get update |
Após executar o nmap, vá até à máquina onde o Snort está instalado e inicie o navegador . Surgirá então uma janela semelhante à mostrada na Figura 7-7.
Você pode explorar muitas das opções do ACID a partir da página inicial, onde encontrará os mais diversos tipos de gráficos e pesquisas que possam ser feitas no banco de dados. As opções mais comuns de pesquisa você encontra nos links da página principal, porém, caso esses tipos de pesquisa não satisfaçam as suas necessidades, clique no link Search e você será levado a uma página de pesquisa avançada, onde poderá especificar exatamente quais opções deseja.
Dentro das páginas de pesquisa você poderá optar por executar algumas ações com os registros obtidos. Entre elas estão:
-
Adicioná-los a um grupo de Alerta (por nome ou ID);
-
Enviá-los por e-mail (uma simples lista com os registros, ou então uma descrição completa dos registros);
-
Apagá-los (somente se o usuário acid tiver permissão delete na base de dados);
-
Arquivar os Alertas.
Estando numa página de pesquisa, você pode clicar sobre o nome de alguns ataques (por exemplo, IDS027 - SCAN-FIN), que o navegador abrirá uma nova janela com o site que contém a descrição desse tipo de ataque.
Kerberos
Apresentação
Kerberos é uma das formas de autenticação de usuários e serviços disponível a partir do Conectiva Linux 8. O protocolo Kerberos foi criado no MIT no final da década de 1980 e vem amadurecendo desde então. A versão disponível e usada hoje em dia é chamada de Kerberos 5 (ou Kerberos V).
A autenticação Kerberos possui as seguintes características:
-
single sign-on: o usuário só precisa fornecer a senha uma vez, normalmente no início da sessão. Depois disso a senha não precisa ser informada outra vez se algum serviço for acessado. Por exemplo, a senha não será mais pedida ao acessar a conta de correio eletrônico;
-
senha criptografada: a senha nunca trafega em texto claro pela rede;
-
autenticação centralizada: a mesma senha é usada para diversos serviços, todos consultam uma base de dados centralizada. Ou seja, o usuário não precisa memorizar várias senhas e uma política de senhas global pode ser facilmente criada;
-
redundância: servidores de autenticação secundários são previstos no protocolo;
-
múltiplos domínios: pode ser criada uma estrutura hierarquizada de autenticação, de forma que usuários de um domínio possam se autenticar em outro (por exemplo, funcionários da filial trabalhando na matriz e vice-versa);
-
configuração do cliente facilitada: boa parte da configuração do cliente pode ser colocada no DNS, de modo que, em muitos casos, não é necessário alterar uma linha sequer na estação de trabalho para que ela comece a usar Kerberos;
-
padrão: Kerberos V é um padrão documentado e implementações diferentes que obedeçam ao mesmo padrão podem conversar entre si. Dentro de certos limites, é possível, por exemplo, se autenticar num servidor W2K, e vice-versa, ou seja, um usuário de um servidor W2K poderá obter tickets de servidores Linux rodando Kerberos V.
Por outro lado, as aplicações que desejarem usar Kerberos terão que ser reescritas em sua grande maioria. No Conectiva Linux, este suporte foi habilitado na maioria dos aplicativos que o tinham disponível:
-
OpenLDAP;
-
Fetchmail;
-
imap (servidores IMAP e POP);
-
Mutt
-
OpenSSH (no repositório experimental apenas, este suporte ainda não está no pacote oficial do site dos autores);
-
PAM (via pam_krb5);
-
CVS;
-
entre outros.
Visão Geral do Kerberos V
A autenticação Kerberos trabalha com tickets. Estes tickets provam que o usuário é ele mesmo e são usados para autenticar este usuário frente aos serviços que ele deseja usar.
Quando um usuário se loga numa máquina, ele obtém o primeiro ticket, chamado de TGT (Ticket Granting Ticket). É com este TGT que o usuário irá pedir acesso aos outros serviços, não sendo mais necessário digitar a senha. Se o usuário agora desejar, por exemplo, acesso ao servidor de e-mail, ele vai apresentar o TGT ao Kerberos e pedir que seja emitido um ticket específico para o servidor de e-mail. O servidor Kerberos irá verificar o TGT e, se tudo estiver certo, responder à requisição do usuário com um ticket para o serviço pedido, no caso, servidor de e-mails. O usuário agora irá contatar o servidor de e-mails e apresentar o novo ticket recebido, ticket esse que o identifica, e terá acesso ao servidor de e-mails. Note que isso tudo ocorre de forma transparente para o usuário. Do ponto de vista do usuário, os e-mails simplesmente começaram a chegar, sem que fosse pedida qualquer senha. A Figura 7-8 a seguir mostra esse processo:
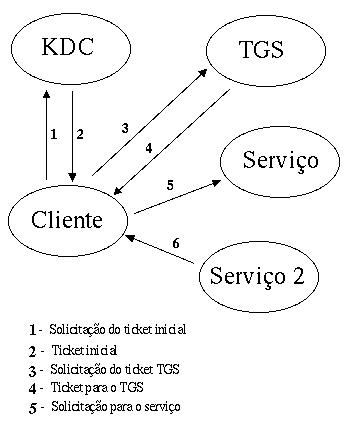
Implementação
Pré-requisitos
Antes de colocar um sistema de autenticação Kerberos em produção é necessário tomar algumas decisões de projeto:
- Domínio
-
Um servidor Kerberos trabalha com o conceito de realm ou domínio. Ele pode ser visto como sendo o autenticador central para as máquinas de um certo domínio. Tecnicamente, o domínio pode ter qualquer nome, mas o padrão é utilizar o mesmo domínio do DNS das máquinas, ou seja, máquinas do domínio .intranet.minhaorganizacao pertenceriam também ao domínio (realm) INTRANET.MINHAORGANIZACAO do Kerberos. Outra convenção é o uso de letras maiúsculas para o domínio Kerberos, mas minúsculas funcionam também sem problemas. Usuários desse domínio (os chamados principals ou principais) terão o seguinte login completo (seguindo o exemplo anterior):
usuário@INTRANET.MINHAORGANIZACAO
É possível e interessante em alguns casos usar mais de um domínio. Por exemplo, poderia existir o MATRIZ.MINHAORGANIZACAO e o FILIAL-RJ.MINHAORGANIZACAO. O Kerberos permite que se faça autenticação entre domínios, ou seja, um usuário do domínio MATRIZ. MINHAORGANIZACAO poderia se autenticar numa viagem à filial do RJ. Isso é chamado de cross-realm authentication. Note que cada domínio pode ter tantos servidores Kerberos quantos quiser, todos com a mesma base de dados. Isso é usado para redundância e para diminuir a carga de um servidor.
- Replicação/servidores escravos (slaves)
-
É importante que um domínio de autenticação tenha pelo menos um servidor secundário, também chamado de escravo (slave). Este servidor secundário é automaticamente usado caso o primário não esteja respondendo, ou também pode ser usado por parte dos clientes para aliviar a carga sobre o servidor primário.
Assim como no caso de servidores secundários de DNS, os servidores secundários do Kerberos são uma cópia de leitura somente da base de dados central. Ou seja, modificações na base primária precisam ser propagadas para os servidores secundários. Ao contrário do DNS, esta propagação é manual no Kerberos. Tipicamente se utilizam scripts de propagação que são executados periodicamente pelo cron no servidor primário.
Como conseqüência da propagação manual e periódica, pode acontecer de uma senha ser trocada no servidor primário e esta modificação ainda não se encontrar no secundário. É possível, no entanto, fazer com que o cliente que estiver usando um servidor secundário consulte excepcionalmente um servidor primário caso a senha do usuário esteja incorreta, ou seja, este inconveniente da propagação pode ser contornado, no mínimo, para as senhas.
Além disso, deve-se:
-
verificar se a rede está configurada.
Instalação
Para instalar o KDC (Key Distribution Center) primário, execute o Synaptic e selecione os seguintes pacotes:
-
krb5
-
krb5-server
Para testes, é interessante instalar também o seguinte pacote:
-
krb5-client
ou utilize o apt-get:
# apt-get install krb5 krb5-server krb5-client |
A Tabela 7-4 contém uma descrição dos pacotes do Kerberos:
Tabela 7-4. Pacotes do Kerberos
| Nome do pacote | Descrição |
|---|---|
| krb5 | Bibliotecas dinâmicas usadas por aplicativos que trabalham com Kerberos. |
| krb5-client | Programas para serem usados numa estação Kerberos, como kinit e kdestroy, entre outros. |
| krb5-server | Contém os programas e arquivos necessários para um servidor Kerberos. |
| krb5-apps-client | Contém os clientes para os servidores "kerberizados", como ktelnet e krsh, entre outros. |
| krb5-doc | Documentação extra sobre o Kerberos. |
Configuração
O primeiro passo é configurar seu domínio no arquivo de configuração do Kerberos em /var/kerberos/krb5kdc/kdc.conf. O arquivo enviado com o pacote contém algumas entradas comentadas que precisam ser modificadas. Este arquivo é dividido em seções cujo nome fica entre colchetes. A seção obrigatória é a que define o domínio e é chamada de [realms]. Abaixo um exemplo para o domínio MINHAORGANIZACAO.DOMINIO:
[realms] |
Basicamente, apenas os parâmetros key_stash_file e database_name precisam ser alterados do padrão, além do nome escolhido para o domínio. Uma explicação detalhada sobre os outros parâmetros podem ser vistos na documentação do Kerberos (pacote krb5-doc).
Após a configuração no arquivo kdc.conf, deve-se criar o banco de dados principal do Kerberos, onde outras informações serão armazenadas mais tarde. Para isto, e continuando com o domínio do exemplo anterior, execute:
# kdb5_util create -r MINHAORGANIZACAO.DOMINIO -s |
Esta senha é a que permite acesso ao banco de dados do Kerberos e deve ser muito bem protegida. A opção -s faz com que seja criado o chamado stash file, que é uma cópia em disco dessa senha e é usada pelos serviços do Kerberos para acessar a base de dados. Se este arquivo não for criado, será necessário fornecer a senha cada vez que os serviços forem iniciados ou outros programas que acessem o banco de dados local sejam executados (como kadmin.local, por exemplo). Os scripts de inicialização fornecidos com o pacote não estão preparados para funcionar sem o stash file. Se você optar por não usar este arquivo de senha, precisará modificar os scripts de inicialização (krb5kdc e kadmind).
Os próximos passos configuram tarefas/serviços necessários para o funcionamento do servidor:
- Criando ACLs (Access Control Lists)
-
O próximo passo é criar um arquivo contendo ACLs para tarefas de administração. Nessas ACLs são definidos quem pode fazer o quê com o banco de dados do Kerberos. Este arquivo é especificado no kdc.conf e é, por padrão, /var/kerberos/krb5kdc/kadm5.acl. O seu formato é:
Principal Permissões Principal de destino (opc.)
É comum usar-se uma instância diferente para um usuário quando ele for executar tarefas administrativas, ao invés de simplesmente tornar o próprio usuário um administrador diretamente. Por exemplo, o usuário:
usuario@MINHAORGANIZACAO.DOMINIO
é um usuário comum do domínio, mas o usuário:
usuario/admin@MINHAORGANIZACAO.DOMINIO
é usuario com a instância de administrador, que requer um outro ticket. As permissões disponíveis são as seguintes:
a: permite acrescentar principais ou políticas;
A: proíbe acrescentar principais ou políticas;
d: permite remover principais ou políticas;
D: proíbe remover principais ou políticas;
m: permite modificar principais ou políticas;
M: proíbe modificar principais ou políticas;
c: permite modificar senhas de principais;
C: proíbe modificar senhas de principais;
i: permite consultas ao banco de dados do Kerberos;
I: proíbe consultas ao banco de dados do Kerberos;
l: permite listar principais ou políticas;
L: proíbe listar principais ou políticas;
*: caractere curinga, vale por todas as permissões;
x: idêntico a "*".
Por exemplo:
*/admin@MINHAORGANIZACAO.DOMINIO *
A linha acima vai dar a todos os "principais" com instância admin todas as permissões possíveis. Neste caso, usuario/admin teria estas permissões, mas não usuario. Outro exemplo:
usuario2@MINHAORGANIZACAO.DOMINIO ali */root@MINHAORGANIZACAO.\
DOMINIOEsta linha permite que o "principal" usuario2 possa acrescentar, listar e fazer consultas sobre qualquer "principal" que tenha a instância root no banco de dados.
- Criar a conta de administrador
-
Agora que as ACLs já estão definidas, pode-se criar uma conta de administrador. Neste exemplo será chamada de admin com instância admin, ou seja, admin/admin:
# kadmin.local -r MINHAORGANIZACAO.DOMINIO
Authenticating as principal root/admin@MINHAORGANIZACAO.DOMINIO \
with password.
kadmin.local: addprinc admin/admin
WARNING: no policy specified for admin/admin@\
MINHAORGANIZACAO.DOMINIO; defaulting to no policy
Enter password for principal "admin/admin@MINHAORGANIZACAO.DOMINIO":
Re-enter password for principal "admin/admin@\
MINHAORGANIZACAO.DOMINIO": Principal \
"admin/admin@MINHAORGANIZACAO.DOMINIO" created.
kadmin.local: - Criar o keytab para a ferramenta de administração
-
O serviço kadmind se encarrega de oferecer o serviço de administração remota do Kerberos. Este serviço possui uma conta na base de dados, ou seja, um principal, que é inserido automaticamente quando a base é criada. O serviço precisa ter acesso à senha dessa conta para poder executar as tarefas de administração pedidas pelo usuário, e portanto é preciso exportar um keytab. Este é um keytab especial, que fica num local definido do arquivo de configuração kdc.conf. O padrão é /var/kerberos/krb5kdc/kadm5.keytab e é criado da seguinte forma:
# kadmin.local -r MINHAORGANIZACAO.DOMINIO
Authenticating as principal root/admin@MINHAORGANIZACAO.DOMINIO \
with password.
kadmin.local: ktadd -k /var/kerberos/krb5kdc/kadm5.keytab \
kadmin/admin@minhaorganizacao.DOMINIO \
kadmin/changepw@MINHAORGANIZACAO.DOMINIO
Entry for principal kadmin/admin@MINHAORGANIZACAO.DOMINIO with kvno 3,\
encryption type Triple DES cbc mode with HMAC/sha1 added to\
keytab WRFILE:/var/kerberos/krb5kdc/kadm5.keytab.
Entry for principal kadmin/admin@MINHAORGANIZACAO.DOMINIO with kvno 3,\
encryption type DES cbc mode with CRC-32 added to keytab WRFILE:\
/var/kerberos/krb5kdc/kadm5.keytab.
Entry for principal kadmin/changepw@MINHAORGANIZACAO.DOMINIO with kvno 3,\
encryption type Triple DES cbc mode with HMAC/sha1 added to\
keytab WRFILE:/var/kerberos/krb5kdc/kadm5.keytab.
Entry for principal kadmin/changepw@MINHAORGANIZACAO.DOMINIO with kvno 3,\
encryption type DES cbc mode with CRC-32 added to keytab WRFILE:\
/var/kerberos/krb5kdc/kadm5.keytab.
kadmin.local:Nota: O script de inicialização do serviço de administração remota (kadmind) automaticamente executa esta operação se este keytab ainda não estiver criado, ou seja, normalmente não é necessário executar o comando acima.
- Iniciar os serviços
-
A configuração básica está completa agora, o restante pode ser feito com o serviço já em execução. Os serviços podem ser iniciados com os comandos:
# service krb5kdc start
# service kadmind startO primeiro comando inicia o KDC, ou seja, o Key Distribution Center. É o que precisa que esteja sendo executado, para que usuários e serviços possam obter seus tickets. O segundo serviço é o de administração remota, que permite que se use remotamente o comando kadmin para acrescentar usuários, removê-los, extrair keytabs, etc.
Estes dois serviços enviam informações sobre seu funcionamento e comportamento para os arquivos /var/log/krb5kdc.log e /var/log/kadmind.log, respectivamente.
Configurando a Replicação
- Criando contas
-
Para que a máquina que será o servidor secundário possa receber os dados do servidor primário, é necessário que ela tenha uma conta na base Kerberos, ou seja, um "principal". Para fazer isso, usa-se a ferramenta de administração kadmin (se for usada localmente, ou seja, no próprio KDC, pode-se usar kadmin.local):
# kadmin.local
Authenticating as principal root/admin@MINHAORGANIZACAO.DOMINIO with \
password.
kadmin.local: addprinc -randkey host/slave.minhaorganizacao.\
dominio
WARNING: no policy specified for host/slave.minhaorganizacao.\
dominio@MINHAORGANIZACAO.DOMINIO; defaulting to no policy
Principal "host/slave.minhaorganizacao.dominio@MINHAORGANIZACAO.\
DOMINIO" created.A "conta" que o escravo precisa ter no mestre, ou seja, o "principal", é do tipo host, pois é considerado uma conta de máquina. A instância desse "principal" é o nome completo (FQDN) da máquina que será o escravo (ou secundário) desse KDC.
- Extraindo os keytabs
-
É necessário agora passar essa "senha" que foi criada para a máquina que será o servidor secundário. A forma mais prática de se fazer isso é rodar kadmin remotamente a partir dessa máquina. Se isso não for possível, o arquivo contendo a senha (o keytab) deverá obrigatoriamente ser copiado de forma segura para o servidor secundário, ou seja, nada de FTP ou outro protocolo que não utilize criptografia. Nem que você precise recorrer a disquetes, não use protocolos de rede inseguros.
Para extrair o keytab do servidor e gravá-lo no servidor secundário, execute:
# kadmin -p admin/admin -r MINHAORGANIZACAO.DOMINIO
Authenticating as principal admin/admin with password.
Enter password:
kadmin: ktadd host/slave.minhaorganizacao.dominio
Entry for principal host/slave.minhaorganizacao.dominio with kvno 4, \
encryption type Triple DES cbc mode with HMAC/sha1 added to keytab \
WRFILE:/etc/krb5.keytab.
Entry for principal host/slave.minhaorganizacao.dominio with kvno 4,\
encryption type DES cbc mode with CRC-32 added to keytab \
WRFILE:/etc/krb5.keytab.Agora o servidor secundário tem a senha (krb5.keytab) necessária para poder se autenticar frente ao servidor primário e receber as informações do banco de dados.
- Acertando permissões de replicação
-
A replicação é feita da base de dados principal para as secundárias usando o serviço kpropd. É necessário criar um arquivo de ACLs que contenha os principais envolvidos na replicação. Por exemplo, se o KDC primário for kerberos.minhaorganizacao.dominio e o KDC secundário for slave.minhaorganizacao.dominio, o arquivo kpropd.acl no diretório /var/kerberos/krb5kdc/ ficaria assim:
host/kerberos.minhaorganizacao.dominio
host/slave.minhaorganizacao.dominioAgora, o serviço de replicação kpropd pode ser iniciado no servidor secundário:
# service kpropd start
- Enviando o banco de dados para os secundários
-
Com o kpropd, iniciado nos servidores secundários, e o arquivo kpropd.acl. listando os principais necessários, pode-se agora enviar o banco de dados para cada um dos servidores secundários.
Primeiro, é preciso fazer um dump do banco de dados, ou seja, criar uma cópia que será usada para a transmissão. No servidor primário, execute:
# kdb5_util dump /var/kerberos/krb5kdc/slave_datatrans
O próximo passo é transmitir o arquivo gerado para cada um dos escravos:
# kprop -f /var/kerberos/krb5kdc/slave_datatrans \
slave.minhaorganizacao.dominio
Database propagation to slave.minhaorganizacao.dominio: SUCCEEDED - Finalizando
-
Por fim, basta iniciar o KDC nos servidores secundários. É necessário regerar o arquivo stash, caso contrário os serviços não conseguirão acessar o banco de dados que acabou de ser transferido. Para isso, use kdb_util em cada um dos servidores secundários:
# kdb5_util stash
kdb5_util: Cannot find/read stored master key while reading master key
kdb5_util: Warning: proceeding without master key
Enter KDC database master key:Agora o serviço KDC pode ser iniciado nos servidores secundários:
# service krb5kdc start