Capítulo 11. Alta Disponibilidade
Introdução
Este capítulo descreverá os conceitos e a terminologia por trás da Alta Disponibilidade, bem como as aplicações e programas de sistema que objetivam aumentar a disponibilidade de servidores Linux, que são parte integrante do Conectiva Linux. Também pode ser usado como um manual para a configuração destas aplicações.
Definição
Para que se entenda a Alta Disponibilidade faz-se necessário, antes de mais nada, perceber que a Alta Disponibilidade não é apenas um produto ou uma aplicação que se instale, e sim uma característica de um sistema computacional. Existem mecanismos e técnicas, blocos básicos, que podem ser utilizados para aumentar a disponibilidade de um sistema. A simples utilização destes blocos, entretanto, não garante este aumento se não for acompanhado de um completo estudo e projeto de configuração.
A Disponibilidade de um sistema computacional, indicada por A(t), é a probabilidade de que este sistema esteja funcionando e pronto para uso em um dado instante de tempo t. Esta disponibilidade pode ser enquadrada em três classes, de acordo com a faixa de valores desta probabilidade. As três classes são: Disponibilidade Básica, Alta Disponibilidade e Disponibilidade Contínua.
Disponibilidade Básica
A Disponibilidade Básica é aquela encontrada em máquinas comuns, sem nenhum mecanismo especial, em software ou hardware, que vise de alguma forma mascarar as eventuais falhas destas máquinas. Costuma-se dizer que máquinas nesta classe apresentam uma disponibilidade de 99% a 99,9%. Isto equivale a dizer que em um ano de operação a máquina pode ficar indisponível por um período de 9 horas a quatro dias. Estes dados são empíricos e os tempos não levam em consideração a possibilidade de paradas planejadas (que serão abordadas mais adiante), porém são aceitas como o senso comum na literatura da área.
Alta Disponibilidade
Adicionando-se mecanismos especializados de detecção, recuperação e mascaramento de falhas, pode-se aumentar a disponibilidade do sistema, de forma que este venha a se enquadrar na classe de Alta Disponibilidade. Nesta classe as máquinas tipicamente apresentam disponibilidade na faixa de 99,99% a 99,999%, podendo ficar indisponíveis por um período de pouco mais de 5 minutos até uma hora em um ano de operação. Aqui se encaixam grande parte das aplicações comerciais de Alta Disponibilidade, como centrais telefônicas.
Disponibilidade Contínua
Com a adição de noves se obtém uma disponibilidade cada vez mais próxima de 100%, diminuindo o tempo de inoperância do sistema de forma que este venha a ser desprezível ou mesmo inexistente. Chega-se então na Disponibilidade Contínua, o que significa que todas as paradas planejadas e não planejadas são mascaradas, e o sistema está sempre disponível.
Objetivos
Como já pode ser percebido de sua definição, o principal objetivo da Alta Disponibilidade é buscar uma forma de manter os serviços prestados por um sistema a outros elementos, mesmo que o sistema em si venha a se modificar internamente por causa de uma falha. Aí está implícito o conceito de mascaramento de falhas, através de redundância ou replicação (termos que serão conceituados mais tarde). Um determinado serviço, que se quer altamente disponível, é colocado por trás de uma camada de abstração, que permita mudanças em seus mecanismos internos mantendo intacta a interação com elementos externos.
Este é o coração da Alta Disponibilidade, uma sub-área da Tolerância a Falhas, que visa manter a disponibilidade dos serviços prestados por um sistema computacional, através da redundância de hardware e reconfiguração de software. Vários computadores juntos agindo como um só, cada um monitorando os outros e assumindo seus serviços caso perceba que algum deles falhou.
Outra possibilidade importante da Alta Disponibilidade é fazer isto com computadores simples, como os que se pode comprar até num supermercado. A complexidade pode estar apenas no software. Mais fácil de desenvolver que o hardware, o software de Alta Disponibilidade é quem se preocupa em monitorar outras máquinas de uma rede, saber que serviços estão sendo prestados, quem os está prestando, e o que fazer quando uma falha é percebida.
Cálculo da Disponibilidade
Em um sistema real, se um componente falha, ele é reparado ou substituído por um novo componente. Se este novo componente falha, é substituído por outro e assim por diante. O componente reparado é tido como no mesmo estado que um componente novo. Durante sua vida útil, um componente pode ser considerado como estando em um destes estados: funcionando ou em reparo. O estado funcionando indica que o componente está operacional e o estado em reparo significa que ele falhou e ainda não foi substituído por um novo componente.
Em caso de defeitos, o sistema vai de funcionando para em reparo, e quando a substituição é feita ele volta para o estado funcionando. Sendo assim, pode-se dizer que o sistema apresenta ao longo de sua vida um tempo médio até apresentar falha (MTTF) e um tempo médio de reparo (MTTR). Seu tempo de vida é uma sucessão de MTTFs e MTTRs, à medida que vai falhando e sendo reparado. O tempo de vida útil do sistema é a soma dos MTTFs nos ciclos MTTF+MTTR já vividos.
De forma simplificada, diz-se que a disponibilidade de um sistema é a relação entre o tempo de vida útil deste sistema e seu tempo total de vida. Isto pode ser representado pela fórmula abaixo:
Disponibilidade = MTTF / (MTTF + MTTR) |
Ao avaliar uma solução de Alta Disponibilidade, é importante levar em consideração se na medição do MTTF são observadas como falhas as possíveis paradas planejadas. Mais considerações sobre este assunto serão tecidas em seções posteriores.
Conceitos
Para se entender corretamente do que se está falando quando se discute uma solução de Alta Disponibilidade, deve-se conhecer os conceitos envolvidos. Não são muitos, porém estes termos são muitas vezes utilizados de forma errônea em literatura não especializada. Antes de mais nada, deve-se entender o que é falha, erro e defeito. Estas palavras, que parecem tão próximas, na verdade designam a ocorrência de algo anormal em três universos diferentes de um sistema computacional.
Falha
Uma falha acontece no universo físico, ou seja, no nível mais baixo do hardware. Uma flutuação da fonte de alimentação, por exemplo, é uma falha. Uma interferência eletromagnética também. Estes são dois eventos indesejados, que acontecem no universo físico e afetam o funcionamento de um computador ou de partes dele.
Erro
A ocorrência de uma falha pode acarretar um erro, que é a representação da falha no universo informacional. Um computador trabalha com bits, cada um podendo conter 0 ou 1. Uma falha pode fazer com que um (ou mais de um) bit troque de valor inesperadamente, o que certamente afetará o funcionamento normal do computador. Uma falha, portanto, pode gerar um erro em alguma informação.
Defeito
Já esta informação errônea, se não for percebida e tratada, poderá gerar o que se conhece por defeito. O sistema simplesmente trava, mostra uma mensagem de erro, ou ainda perde os dados do usuário sem maiores avisos. Isto é percebido no universo do usuário.
Recapitulando, uma falha no universo físico pode causar um erro no universo informacional, que por sua vez pode causar um defeito percebido no universo do usuário. A Tolerância a Falhas visa exatamente acabar com as falhas, ou tratá-las enquanto ainda são erros. Já a Alta Disponibilidade permite que máquinas travem ou errem, contanto que exista outra máquina para assumir seu lugar.
Para que uma máquina assuma o lugar de outra, é necessário que descubra de alguma forma que a outra falhou. Isso é feito através de testes periódicos, cujo período deve ser configurável, nos quais a máquina secundária testa não apenas se a outra está ativa, mas também fornecendo respostas adequadas a requisições de serviço. Um mecanismo de detecção equivocado pode causar instabilidade no sistema. Por serem periódicos, nota-se que existe um intervalo de tempo durante o qual o sistema pode estar indisponível sem que a outra máquina o perceba.
Failover
O processo no qual uma máquina assume os serviços de outra, quando esta última apresenta falha, é chamado failover. O failover pode ser automático ou manual, sendo o automático o que normalmente se espera de uma solução de Alta Disponibilidade. Ainda assim, algumas aplicações não críticas podem suportar um tempo maior até a recuperação do serviço, e portanto podem utilizar failover manual[1]. Além do tempo entre a falha e a sua detecção, existe também o tempo entre a detecção e o reestabelecimento do serviço. Grandes bancos de dados, por exemplo, podem exigir um considerável período de tempo até que atualizem os índices de suas tabelas e, durante este tempo, o serviço ainda estará indisponível.
Para se executar o failover de um serviço, é necessário que as duas máquinas envolvidas possuam recursos equivalentes. Um recurso pode ser uma placa de rede, um disco rígido, os dados neste disco, e todo e qualquer elemento necessário à prestação de um determinado serviço. É vital que uma solução de Alta Disponibilidade mantenha recursos redundantes com o mesmo estado, de forma que o serviço possa ser retomado sem perdas.
Dependendo da natureza do serviço, executar um failover significa interromper as transações em andamento, perdendo-as, sendo necessário reiniciá-las após o failover. Em outros casos, significa apenas um retardo até que o serviço esteja novamente disponível. Nota-se que o failover pode ou não ser um processo transparente, dependendo da aplicação envolvida.
Failback
Ao ser percebida a falha de um servidor, além do failover é obviamente necessário que se faça manutenção no servidor falho. Ao ser recuperado de uma falha, este servidor será recolocado em serviço, e então se tem a opção de realizar o processo inverso do failover, que se chama failback. O failback é portanto o processo de retorno de um determinado serviço de uma outra máquina para sua máquina de origem. Também pode ser automático, manual ou até mesmo indesejado. Em alguns casos, em função da possível nova interrupção na prestação de serviços, o failback pode não ser atraente.
Missão
Quando se calcula a disponibilidade de um sistema, é importante que se observe o conceito de missão. Missão de um sistema é o período de tempo no qual ele deve desempenhar suas funções sem interrupção. Por exemplo, uma farmácia, que funcione das 8h às 20h, não pode ter seu sistema fora do ar durante este período de tempo. Se este sistema vier a apresentar defeitos fora deste período, ainda que indesejados, estes defeitos não atrapalham em nada o andamento correto do sistema quando ele é necessário. Uma farmácia 24h obviamente tem uma missão contínua, de forma que qualquer tipo de parada deve ser mascarada.
A Alta Disponibilidade visa eliminar as paradas não planejadas. Porém, no caso da primeira farmácia, as paradas planejadas não devem acontecer dentro do período de missão. Paradas não planejadas decorrem de defeitos, já paradas planejadas são aquelas que se devem a atualizações, manutenção preventiva e atividades correlatas. Desta forma, toda parada dentro do período de missão pode ser considerada uma falha no cálculo da disponibilidade.
Uma aplicação de Alta Disponibilidade pode ser projetada inclusive para suportar paradas planejadas, o que pode ser importante, por exemplo, para permitir a atualização de programas por problemas de segurança, sem que o serviço deixe de ser prestado.
A Solução Conectiva para Alta Disponibilidade
A Conectiva tem participado de projetos internacionais de Alta Disponibilidade, colaborando com a elaboração de diversos programas que suprem funcionalidades básicas na construção de ambientes de Alta Disponibilidade. O interesse em trabalhar na integração de diversas tecnologias e estendê-las individualmente vem do objetivo de prover uma solução simples e flexível, que possa ser otimimizada para as particularidades de cada aplicação. Todos estes projetos seguem a filosofia do Software Livre, assim como a solução apresentada pela Conectiva em seu Conectiva Linux.
Neste espírito, a solução é baseada em quatro blocos básicos, que são: replicação de disco, monitoração de nodos, monitoração de serviços e sistema de arquivos robusto. Estes quatro blocos podem ser utilizados em conjunto ou individualmente, possibilitando a criação de soluções com failover e failback, automáticos ou manuais, com ou sem replicação de dados, e mesmo suportando paradas planejadas. Esta solução foi idealizada para um cluster de dois nodos.
Monitoração de nodos
A monitoração de nodos é realizada pelo heartbeat. Ele é o responsável por testar periodicamente os nodos do cluster, coordenando as ações de failover e failback. As soluções que utilizam reativação automática de serviços serão baseadas neste pacote.
Replicação de disco
A replicação de disco é de responsabilidade do DRBD, um driver de bloco para o kernel que cria um dispositivo de bloco[2] virtual, consistindo tanto de um disco real local quanto de uma conexão de rede, que terá na outra ponta outro driver DRBD atuando como secundário. Tudo aquilo que é escrito no dispositivo virtual é escrito no disco local e também enviado para o outro driver, que fará a mesma operação em seu disco local. Com isto se obtém dois nodos com discos exatamente iguais, até o instante da falha. As aplicações que trabalham com dados dinâmicos ou atualizados com muita freqüência se beneficiam deste driver.
| Atenção |
|
Configurações com centenas de gigabytes e/ou muito volumes gerenciados pelo DRBD devem ser bem testadas antes de serem colocadas em produção, pois o DRBD ainda está em desenvolvimento e algumas situações extremas podem não ter sido testadas. |
Sistema de arquivos
Dados replicados ou não, é importante que o sistema de arquivos esteja consistente. Nem todos os sistemas de arquivos garantem isso, portanto para esta solução se escolheu trabalhar com o Ext3 Filesystem. Este sistema de arquivos trabalha com journal, o que significa que todas as alterações de dados são antes registradas no disco para que, caso o sistema venha a falhar durante este processo, a transação possa ser recuperada quando o sistema voltar. Isto confere agilidade ao processo de recuperação de falhas, bem como aumenta muito a confiabilidade das informações armazenadas.
Monitoração de serviços
A monitoração de serviços é feita através do Mon, um super- escalonador de testes que pode verificar centenas de máquinas e serviços de forma rápida e ágil, enviando alertas para endereços de correio eletrônico, pagers ou telefones celulares, garantindo que os administradores dos serviços estejam sempre bem informados sobre seu estado de operação. Suporta dependências entre testes, portanto não perde tempo verificando se um servidor de HTTP está respondendo em uma máquina que sabe estar inoperante. Um alerta pode até mesmo tentar recuperar a situação automaticamente ou reiniciar uma máquina, caso a falha ocorra em um horário de difícil manutenção.
Implementação
Pré-requisitos
Deve-se ter disponível dois computadores, onde a configuração será idêntica para os dois.
Instalação
Utilize o Synaptic para instalar o pacote do DRBD:
-
drbd-utils
-
linuxconf-cl_ha_conf
-
linuxconf-drbdconf
ou utilize o apt:
# apt-get install drbd-utils |
DRBD
Tendo dois computadores, chamados aqui de ha1 e ha2, efetue estas configurações de forma idêntica nos dois.
Abra o Linuxconf e acesse o menu Configuração -> Rede -> Tarefas de servidor -> Dispositivos DRBD -> Adicionar. Observe a Figura 11-1.
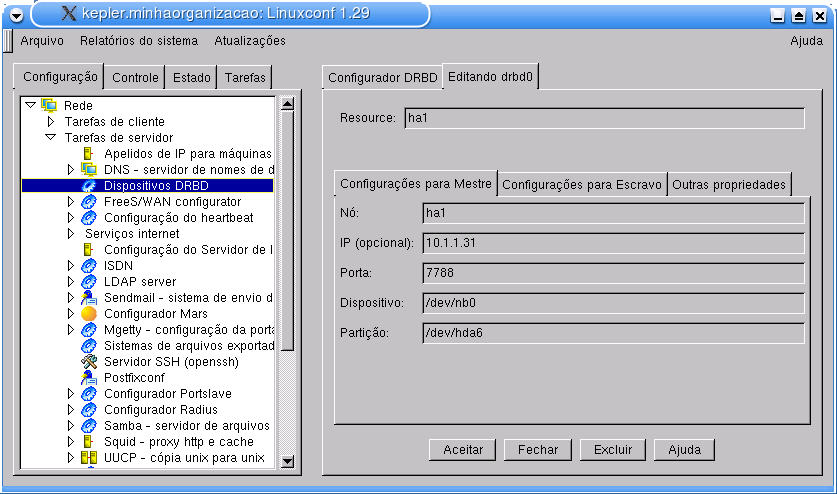
No campo Nó coloque o nome da máquina do mestre, e no campo Partição a partição para o DRBD. Efetue estas configurações também para o escravo, através da aba Configurações para Escravo. Clique em Aceitar.
Nota: A opção Taxa de sinc. (Kb/s) na aba Outras propriedades deve ser modificada para se adaptar de acordo com a banda de rede disponível. O valor mostrado na tela é meramente um exemplo.
Finalize o Linuxconf; ele irá perguntar se você deseja reinicializar os serviços; clique em Sim.
Heartbeat
Instalação
Use o Synaptic para instalar os pacotes do Heartbeat:
-
drbd-utils-heartbeat
-
heartbeat-stonith
-
heartbeat
ou utilize o apt:
# apt-get install drbd-utils-heartbeat heartbeat-stonith heartbeat |
Configuração
As configurações do heartbeat podem ser feitas através do módulo do arquivo /etc/ha.d/haresources. Este arquivo contém uma lista dos serviços que serão gerenciados pelo heartbeat, dos endereços IP a serem utilizados e de quem é o servidor primário para cada grupo de serviços.
O exemplo abaixo exibe este arquivo:
# /etc/ha.d/haresources |
Alguns detalhes importantes devem ser considerados sobre esta configuração:
-
O "nome-do-nodo" deve ser o nome retornado pela execução do comando uname -n, em cada um dos nodos citados no arquivo.
-
Os endereços IP listados neste arquivo não devem ser endereços fixos de nenhuma máquina na rede. Estes endereços serão adicionados às interfaces corretas, pelo heartbeat, quando os serviços forem iniciados num dos nodos. São os chamados endereços virtuais, citados na documentação que acompanha o heartbeat.
-
Os recursos são inicializados na ordem em que são listados, recebendo o parâmetro start. São finalizados em ordem inversa, com o parâmetro stop.
-
Estes recursos devem comportar-se como initscripts SystemV (scripts de inicialização de serviços), respeitando o padrão LSB para códigos de retorno das operações start, stop e status.
-
Os recursos citados podem utilizar outros endereços IP virtuais.
O próximo passo corresponde a configuração do cluster; o arquivo responsável por esta configuração está localizado em /etc/ha.d/ha.cf.
A seguir está descrito um exemplo de arquivo de configuração, com as principais opções devidamente configuradas e comentadas. O arquivo de exemplo que acompanha o heartbeat possui outras opções mais avançadas, mas desnecessárias para a vasta maioria das configurações.
Das várias possibilidades de configuração do arquivo ha.cf, o indispensável é um conjunto de nodos ("node ...") e uma ou mais interfaces ("serial, bcast, mcast ou ucast").
Excetuando-se a configuração ucast, que é diferente nos dois nodos, e as configurações de porta serial, que podem ser diferentes, o arquivo ha.cf é igual nos dois nodos. Segue o arquivo de exemplo:
# /etc/ha.d/ha.cf |
Chaves de autenticação de mensagens
Estas opções são configuradas no arquivo /etc/ha.d/authkeys.
Deve-se selecionar uma das três possibilidades de autenticação de mensagens: crc, sha1 ou md5. As duas últimas pedem uma chave para ser usada na autenticação.
O arquivo authkeys deve possuir direitos de leitura e escrita apenas para root. Isso pode ser assegurando executando-se:
# chmod 600 /etc/ha.d/authkeys |
Segue um exemplo de arquivo de configuração:
# /etc/ha.d/authkeys |
Referências
-
PFISTER, Gregory F. In Search of Clusters. Prentice-Hall, 1998.
-
JALOTE, Pankaj. Fault Tolerance in Distributed Systems. Prentice-Hall, 1994.
-
PRADHAN, Dhiraj K. Fault-Tolerant Computer System Design. Prentice-Hall, 1996.
-
BIRMAN, Kenneth P. Building Secure and Reliable Network Applications. Manning, 1996.
Links: