Capítulo 9. RAID
- Índice
- Apresentação
- Implementação
- Referências
Apresentação
RAID é acrônimo para Redundant Array of Inexpensive Disks[1]. Este arranjo é usado como um meio para criar um subsistema de unidade de disco, rápido e confiável, através de vários discos individuais.
Apesar do RAID ter sido feito para melhorar a confiabilidade do sistema, através da adição de redundância, pode também levar a uma falsa sensação de segurança e confiança quando usado incorretamente. Esta falsa confiança pode acarretar em grandes desastres. Particularmente, o RAID é feito para proteger falhas no disco, não para proteger falhas de energia ou erros do operador.
Falhas de energia, bugs no desenvolvimento do kernel ou erros de administradores e de operadores podem danificar os dados de uma forma irrecuperável. RAID não é um substituto apropriado para executar um backup do seu sistema. Saiba o que você está fazendo, faça testes, seja conhecedor e ciente de todos os detalhes que envolvem a implementação de RAID.
RAID permite que o computador ganhe desempenho nas operações de acesso a disco, e da mesma forma, rápida recuperação em caso de perda de algum disco. O tipo mais comum de arranjo de unidades é um sistema ou uma controladora que possibilita o uso de múltiplas unidades de disco rígido, configuradas para que o sistema operacional se comporte como se existisse apenas um disco instalado no computador.
RAID Via Hardware e Via Software
RAID pode ser implementado por hardware, na forma de controladoras especiais de disco, ou por software, como um módulo do kernel que fica dividido entre a controladora de disco de baixo nível e o sistema de arquivos acima dele.
RAID Via Hardware
RAID por hardware é sempre uma controladora de disco, isto é, um dispositivo que pode através de um cabo conectar os discos. Geralmente ele vem na forma de uma placa adaptadora que pode ser "plugada" em um slot ISA/EISA/PCI/S-Bus/MicroChannel. Entretanto, algumas controladoras RAID vêm na forma de uma caixa que é conectada através de um cabo entre o sistema controlador de disco e os dispositivos de disco.
RAIDs pequenos podem ser ajustados nos espaços para disco do próprio computador; outros maiores podem ser colocados em um gabinete de armazenamento com seu próprio espaço para disco e suprimento de energia. O hardware mais recente de RAID usado com a mais recente e rápida CPU irá geralmente fornecer o melhor desempenho total, porém com um preço significante. Isto porque a maioria das controladoras RAID vem com processadores especializados na placa e memória cache, que pode eliminar uma quantidade de processamento considerável da CPU. As controladoras RAID também podem fornecer altas taxas de transferência através do cache da controladora.
Um hardware de RAID antigo pode atuar como um desacelerador, quando usado com uma CPU mais nova: DSP[2] e caches antigos podem atuar como um gargalo, e este desempenho pode ser freqüentemente superado por um RAID de software puro.
RAID por hardware geralmente não é compatível entre diferentes tipos, fabricantes e modelos: se uma controladora RAID falhar, é melhor que ela seja trocada por outra controladora do mesmo tipo. Para uma controladora de RAID via hardware poder ser usada no Linux ela precisa contar com utilitários de configuração e gerenciamento, feitos para este sistema operacional e fornecidos pelo fabricante da controladora.
DPT
É possível configurar RAID via hardware SCSI, contando com suporte no Linux e documentação de uma forma geral, através de adaptadores da DPT. Informações de instalação e configuração podem ser obtidas no site DPT-RAID .
Controladoras Suportadas
Uma controladora de RAID via hardware e bem suportada é aquela fabricada pela DPT . Entretanto, existem diversas outras controladoras que funcionam no Conectiva Linux. Isto inclui algumas controladoras fabricadas pela Syred , ICP-Vortex e BusLogic . Para obter mais informações sobre este assunto verifique a página sobre Soluções de RAID para o Linux .
Entre as controladoras DPT, essencialmente todas as controladoras SmartRAID IV são suportadas.
Controladoras ICP Vortex
A ICP Vortex tem uma linha completa de controladoras de arranjos de discos com suporte ao Linux. O driver ICP está no kernel do Linux desde a versão 2.0.31. Todas as distribuições principais do Linux têm suporte às controladoras ICP, como controladoras para boot e instalação. O sistema RAID pode ser facilmente configurado com seu próprio ROMSETUP, ou seja, você não precisa utilizar outros sistemas operacionais para fazer a configuração.
Com o utilitário de monitoramento GDTMON é possível gerenciar por completo o sistema RAID ICP durante a operação. É possível também verificar taxas de transferência, configurar os parâmetros da controladora e dos discos rígidos, substituir discos defeituosos, etc. Atualmente estão disponíveis vários modelos para os mais diversos níveis de RAID que você venha a utilizar.
Tipos de Hardware
Tipo Controladora
Tendo várias opções de controladoras, é necessário pensar cuidadosamente sobre o que você quer fazer. Dependendo do que quer fazer e do nível de RAID que irá usar, algumas controladoras podem ser melhores que outras. Adaptadores SCSI a SCSI[3] podem não ser tão bons quanto adaptadores baseados em host[4], por exemplo. Michael Neuffer <neuffer@kralle.zdv.uni-mainz.de>, o autor do driver EATA-DMA, tem uma boa discussão sobre isto em sua página: Linux High Performance SCSI and RAID .
Tipo Encapsulado
O tipo encapsulado é ligado diretamente à habilidade de troca "à quente"[5] da unidade e aos sistemas de advertência, ou seja, exibe indicação de falhas da unidade e que tipo de tratamento sua unidade receberá. Um exemplo para isto pode ser refrigeração redundante e fornecimento de energia. Os encapsulamentos fornecidos pela DPT, HP®, IBM® e Compaq® trabalham extremamente bem, mas têm um custo alto também.
RAID Via Software
RAID via software é uma configuração de módulos do kernel, juntamente com utilitários de administração que implementam RAID puramente por software, e não requer um hardware especializado. Pode ser utilizado o sistema de arquivos ext2, ext3, DOS-FAT ou outro.
Este tipo de RAID é implementado através dos módulos MD[6] do kernel do Linux e das ferramentas relacionadas.
RAID por software, por ter sua natureza no software, tende a ser muito mais flexível que uma solução por hardware. O lado negativo é que ele em geral requer mais ciclos e capacidade de CPU para funcionar bem, quando comparado a um sistema de hardware. Ele oferece uma importante e distinta característica: opera sobre qualquer dispositivo do bloco podendo ser um disco inteiro (por exemplo, /dev/sda), uma partição qualquer (por exemplo, /dev/hdb1), um dispositivo de loopback (por exemplo, /dev/loop0) ou qualquer outro dispositivo de bloco compatível, para criar um único dispositivo RAID. Isso diverge da maioria das soluções de RAID via hardware, onde cada grupo junta unidades de disco inteiras em um arranjo.
Comparando as duas soluções, o RAID via hardware é transparente para o sistema operacional, e isto tende a simplificar o gerenciamento. Via software, há de longe mais opções e escolhas de configurações, fazendo com que o assunto se torne mais complexo.
O Controlador de Múltiplos Dispositivos (MD)
O controlador MD é usado para agrupar uma coleção de dispositivos de bloco, em um único e grande dispositivo de bloco. Normalmente, um conjunto de dispositivos SCSI e IDE são configurados em um único dispositivo MD.
As extensões do controlador MD implementam modo linear, RAID-0 (stripping), RAID-1 (espelhamento[7]), RAID-4 e RAID-5 por software. Isto quer dizer que, com MD, não é necessário hardware especial ou controladoras de disco para obter a maioria dos benefícios de RAID.
| Atenção |
|
A administração de RAID no Linux não é uma tarefa trivial, e é mais voltada para administradores de sistema experientes. A teoria da operação é complexa. As ferramentas do sistema exigem modificações nos scripts de inicialização. E recuperar-se de uma falha no disco não é uma tarefa simples, é passível de erros humanos. RAID não é para iniciantes, e qualquer benefício em busca de confiabilidade e desempenho pode ser facilmente acrescido de complexidade extra. Certamente, unidades de disco evoluídas são muito confiáveis, e controladoras e CPUs avançadas são muito potentes. Você pode obter mais facilmente os níveis de confiabilidade e desempenho desejados, comprando hardware de alta qualidade e potência. Os kernels do Linux da série 2.4.x incluem o suporte a RAID por software por padrão. O mesmo nível de suporte a RAID pode ser obtido nos kernels da série 2.2 aplicando-se correções ou patches (veja no FTP do kernel ). Os kernels da série 2.4.x suportam RAID via software com sistema de arquivos journalled (por exemplo, ext3), diferente do kernel 2.2.x, que não possuía este suporte. |
Níveis de RAID
As diferentes maneiras de combinar os discos em um só, chamados de níveis de RAID[8], podem fornecer tanto grande eficiência de armazenamento como simples espelhamento, ou podem alterar o desempenho de latência (tempo de acesso). Podem também fornecer desempenho da taxa de transferência de dados para leitura e para escrita, enquanto continuam mantendo a redundância. Novamente, isto é ideal para prevenir falhas.
Os diferentes níveis de RAID apresentam diferentes desempenho, redundância, capacidade de armazenamento, confiabilidade e características de custo. A maioria, mas nem todos os níveis de RAID, oferece redundância à falha de disco. Dos que oferecem redundância, RAID-1 e RAID-5 são os mais populares. RAID-1 oferece melhor desempenho, enquanto que RAID-5 fornece um uso mais eficiente do espaço disponível para o armazenamento dos dados.
De qualquer modo, o ajuste de desempenho é um assunto bastante diferente, dependente de uma grande variedade de fatores, como o tipo da aplicação, os tamanhos dos discos, blocos e arquivos.
Existe uma variedade de tipos diferentes e implementações de RAID, cada uma com suas vantagens e desvantagens. Por exemplo, para colocar uma cópia dos mesmos dados em dois discos (operação chamada de espelhamento de disco[9] ou RAID nível 1), pode-se acrescentar desempenho de leitura, lendo alternadamente cada disco do espelho. Em média, cada disco é menos usado, por estar sendo usado em apenas metade da leitura (para dois discos), ou um terço (para 3 discos), etc. Além disso, um espelho pode melhorar a confiabilidade: se um disco falhar, o(s) outro(s) disco(s) têm uma cópia dos dados.
A seguir serão descritos os diferentes níveis de RAID, no contexto de implementação de RAID por software no Linux.
RAID-linear
É uma simples concatenação de partições para criar uma grande partição virtual. Isto é possível se você tem várias unidades pequenas, e quer criar uma única e grande partição. Esta concatenação não oferece redundância, e de fato diminui a confiabilidade total: se qualquer um dos discos falhar, a partição combinada irá falhar.
RAID-0
A grande maioria dos níveis de RAID envolve uma técnica de armazenamento chamada de segmentação de dados (data stripping). A implementação mais básica dessa técnica é conhecida como RAID-0 e é suportada por muitos fabricantes. Contudo, pelo fato de este nível de arranjo não ser tolerante a falhas, RAID-0 não é verdadeiramente RAID, ao menos que seja usado em conjunção com outros níveis de RAID.
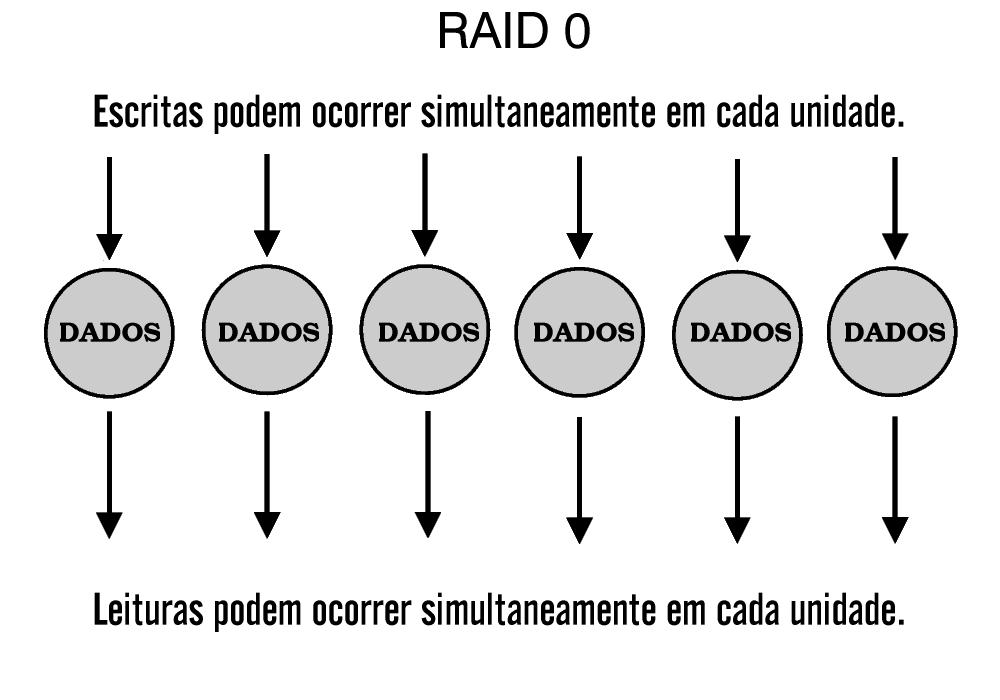
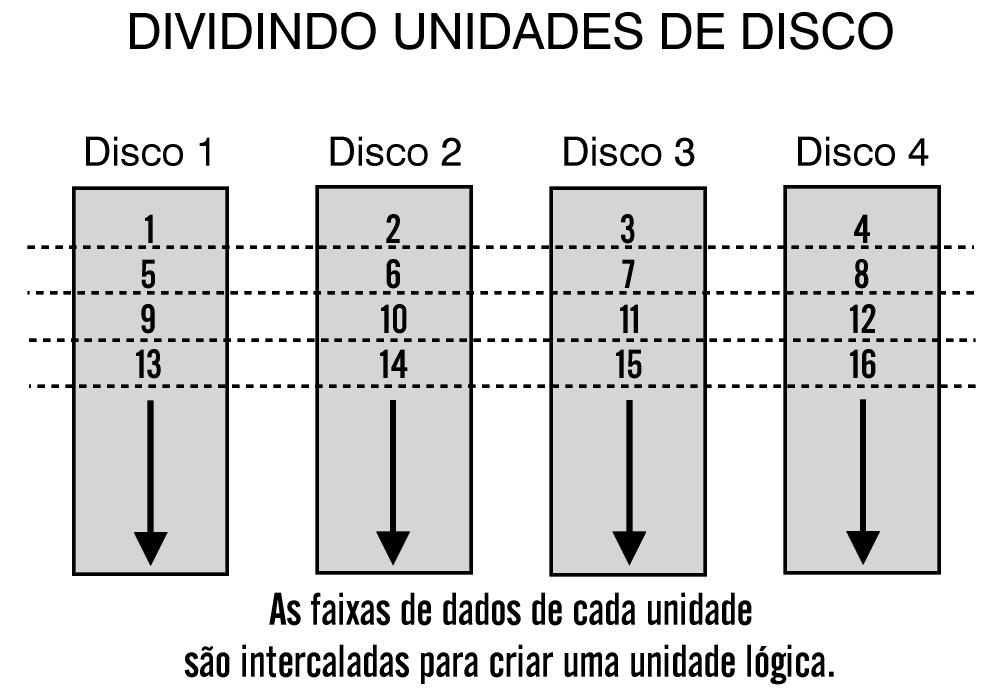
Segmentação (stripping) é um método de mapeamento de dados sobre o meio físico de um arranjo, que serve para criar um grande dispositivo de armazenamento. Os dados são subdivididos em segmentos consecutivos ou stripes que são escritos seqüencialmente através de cada um dos discos de um arranjo. Cada segmento tem um tamanho definido em blocos.
Por exemplo, sabendo que o tamanho de cada segmento está definido em 64 kbytes, e o arranjo de discos contém 2 discos, quando um arquivo de 128 kbytes for gravado, os primeiros 64 kbytes serão gravados no primeiro disco, sendo que os últimos 64 kbytes irão para o segundo disco, e normalmente isso é feito em paralelo, aumentando consideravelmente o desempenho.
Um arranjo desse tipo pode oferecer um melhor desempenho, quando comparada a um disco individual, se o tamanho de cada segmento for ajustado de acordo com a aplicação que utilizará o arranjo:
-
Em um ambiente com uso intensivo de E/S ou em um ambiente de banco de dados onde múltiplas requisições concorrentes são feitas para pequenos registros de dados, um segmento de tamanho grande é preferencial. Se o tamanho de segmento para um disco é grande o suficiente para conter um registro inteiro, os discos do arranjo podem responder independentemente para as requisições simultâneas de dados.
-
Em um ambiente onde grandes registros de dados são armazenados, segmentos de pequeno tamanho são mais apropriados. Se um determinado registro de dados estende-se através de vários discos do arranjo, o conteúdo do registro pode ser lido em paralelo, aumentando o desempenho total do sistema.
Arranjos RAID-0 podem oferecer alto desempenho de escrita, se comparados a verdadeiros níveis de RAID, por não apresentarem carga adicional[10] associada com cálculos de paridade ou com técnicas de recuperação de dados. Esta mesma falta de previsão para reconstrução de dados perdidos indica que esse arranjo deve ser restrito ao armazenamento de dados não críticos e combinado com eficientes programas de backup.
RAID-1
A forma mais simples de arranjo tolerante a falhas é o RAID-1. Baseado no conceito de espelhamento (mirroring), este arranjo consiste de vários grupos de dados armazenados em dois ou mais dispositivos. Apesar de muitas implementações de RAID-1 envolverem dois grupos de dados (daí o termo espelho ou mirror), três ou mais grupos podem ser criados se a alta confiabilidade for desejada.
Se ocorre uma falha em um disco de um arranjo RAID-1, leituras e gravações subseqüentes são direcionadas para o(s) disco(s) ainda em operação. Os dados então são reconstruídos em um disco de reposição (spare disk) usando dados do(s) disco(s) sobrevivente(s). O processo de reconstrução do espelho tem algum impacto sobre o desempenho de E/S do arranjo, pois todos os dados terão de ser lidos e copiados do(s) disco(s) intacto(s) para o disco de reposição.
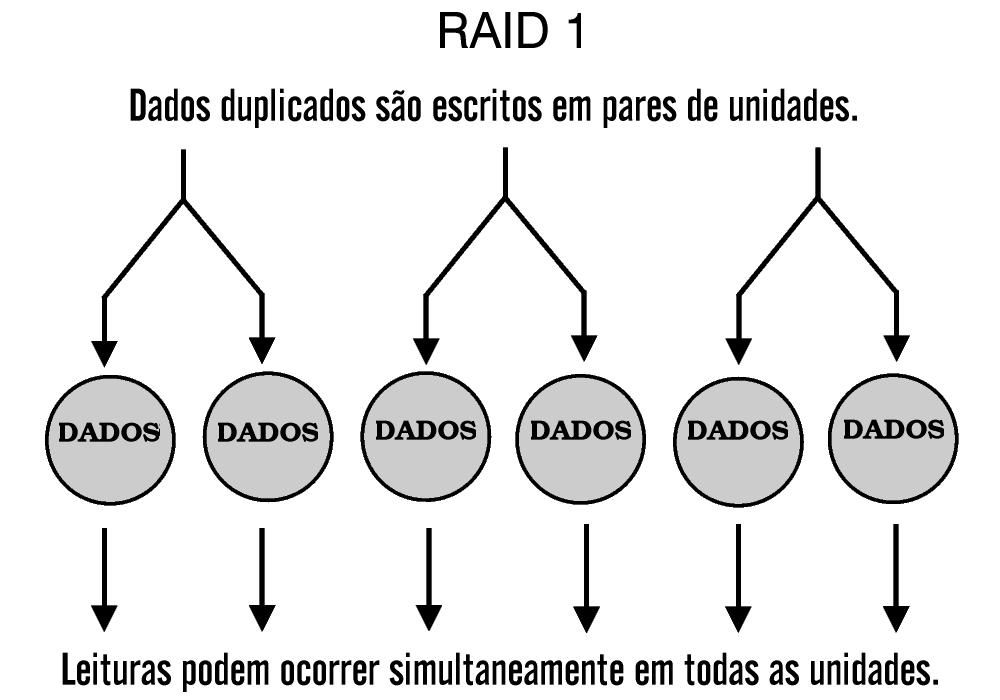
RAID-1 oferece alta disponibilidade de dados, porque no mínimo dois grupos completos são armazenados. Conectando os discos primários e os discos espelhados em controladoras separadas, pode-se aumentar a tolerância a falhas pela eliminação da controladora como ponto único de falha.
Entre os não-híbridos, este nível tem o maior custo de armazenamento por requerer capacidade suficiente para armazenar no mínimo dois grupos de dados. Este nível é melhor adaptado para servir pequenas base de dados ou sistemas de pequena escala que necessitem confiabilidade.
RAID-2 e RAID-3
Raramente são usados, e tornaram-se obsoletos pelas novas tecnologias de disco. RAID-2 é similar ao RAID-4, mas armazena informação ECC (error correcting code), que é a informação de controle de erros, no lugar da paridade. Este fato possibilitou uma pequena proteção adicional, visto que todas as unidades de disco mais novas incorporaram ECC internamente.
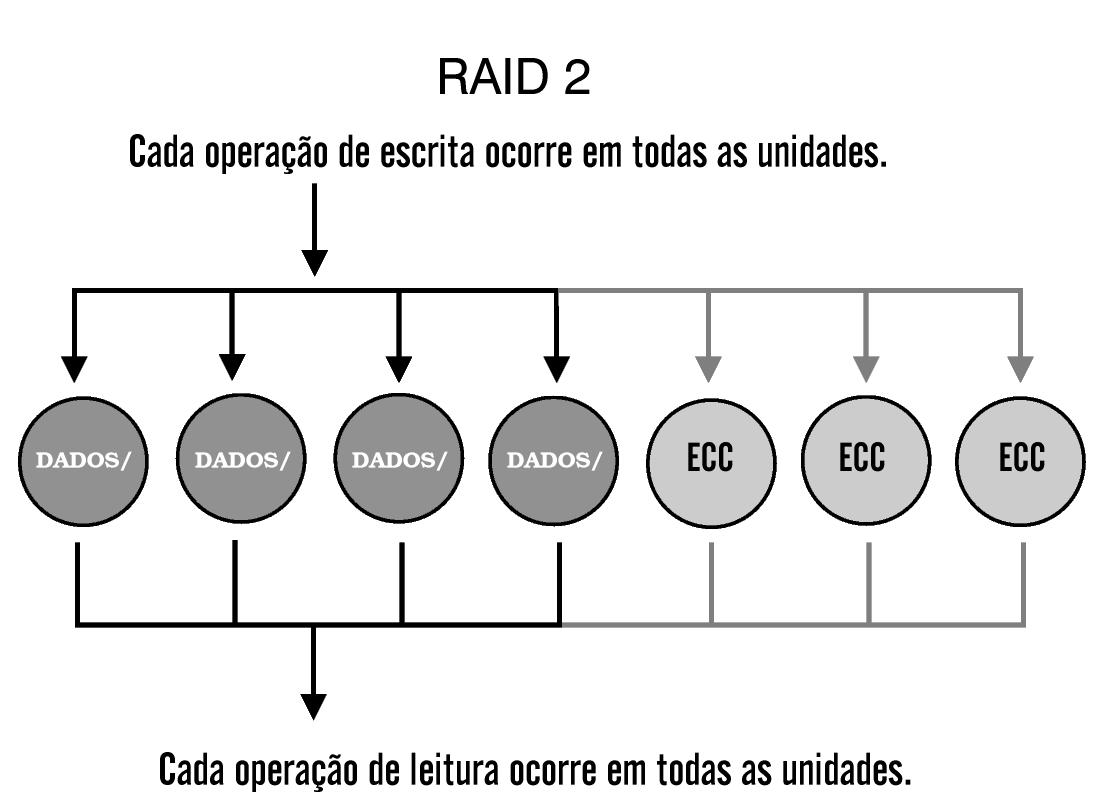
RAID-2 pode oferecer maior consistência dos dados se houver queda de energia durante a escrita. Baterias de segurança e um desligamento correto, porém, podem oferecer os mesmos benefícios. RAID-3 é similar ao RAID-4, exceto pelo fato de que ele usa o menor tamanho possível para a stripe. Como resultado, qualquer pedido de leitura invocará todos os discos, tornando as requisições de sobreposição de E/S difíceis ou impossíveis.
A fim de evitar o atraso em razão da latência rotacional, o RAID-3 exige que todos os eixos das unidades de disco estejam sincronizados. A maioria das unidades de disco mais recentes não possuem a habilidade de sincronização do eixo, ou se são capazes disto, faltam os conectores necessários, cabos e documentação do fabricante. Nem RAID-2 e nem RAID-3 são suportados pelos drivers de RAID por software no Linux.
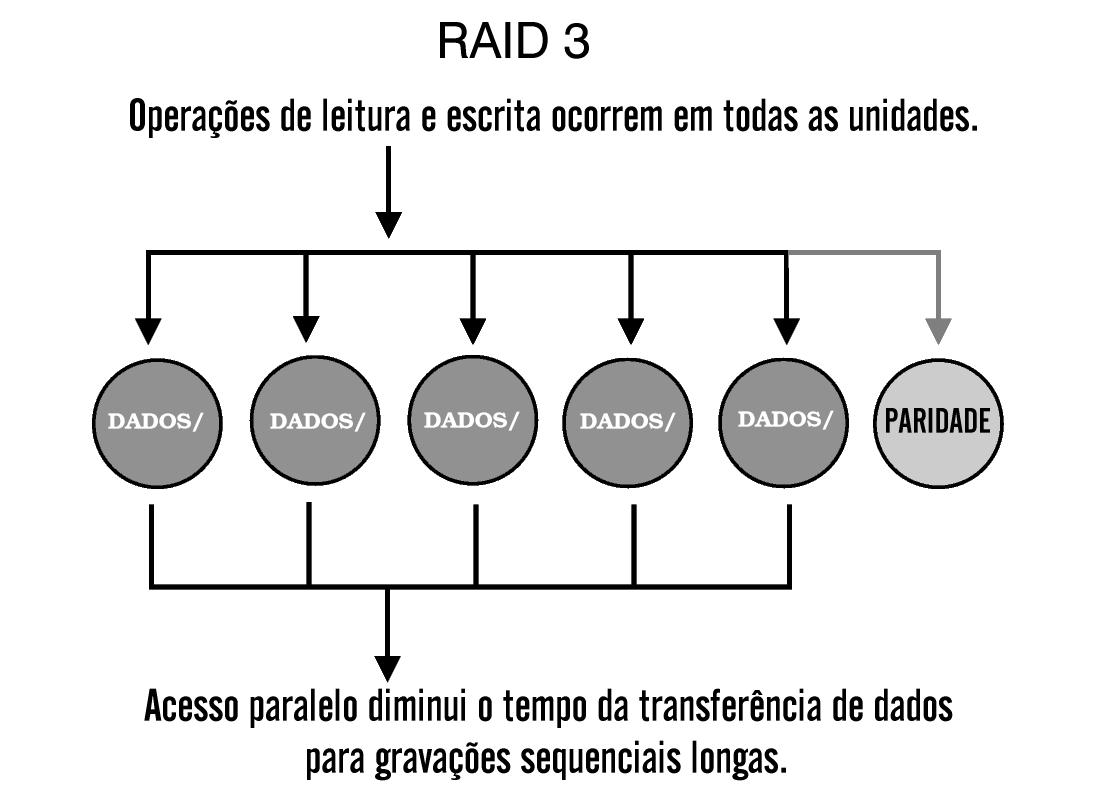
RAID-4
Este é um tipo de arranjo segmentado, mas incorpora um método de proteção de dados mais prático. Ele usa informações sobre paridade para a recuperação de dados e as armazena em disco dedicado. Os discos restantes, usados para dados, são configurados para usarem grandes (tamanho medido em blocos) segmentos de dados, suficientemente grandes para acomodar um registro inteiro. Isto permite leituras independentes da informação armazenada, fazendo de RAID-4 um arranjo perfeitamente ajustado para ambientes transacionais que requerem muitas leituras pequenas e simultâneas.
Arranjos RAID-4 e outros arranjos que utilizam paridade fazem uso de um processo de recuperação de dados mais dinâmico que arranjos espelhados, como RAID-1. A função ou exclusivo (XOR) dos dados e informações sobre paridade dos discos restantes é computada para reconstruir os dados do disco que falhou. Pelo fato de que todos os dados sobre paridade são escritos em um único disco, esse disco funciona como um gargalo durante as operações de escrita, reduzindo o desempenho durante estas operações.
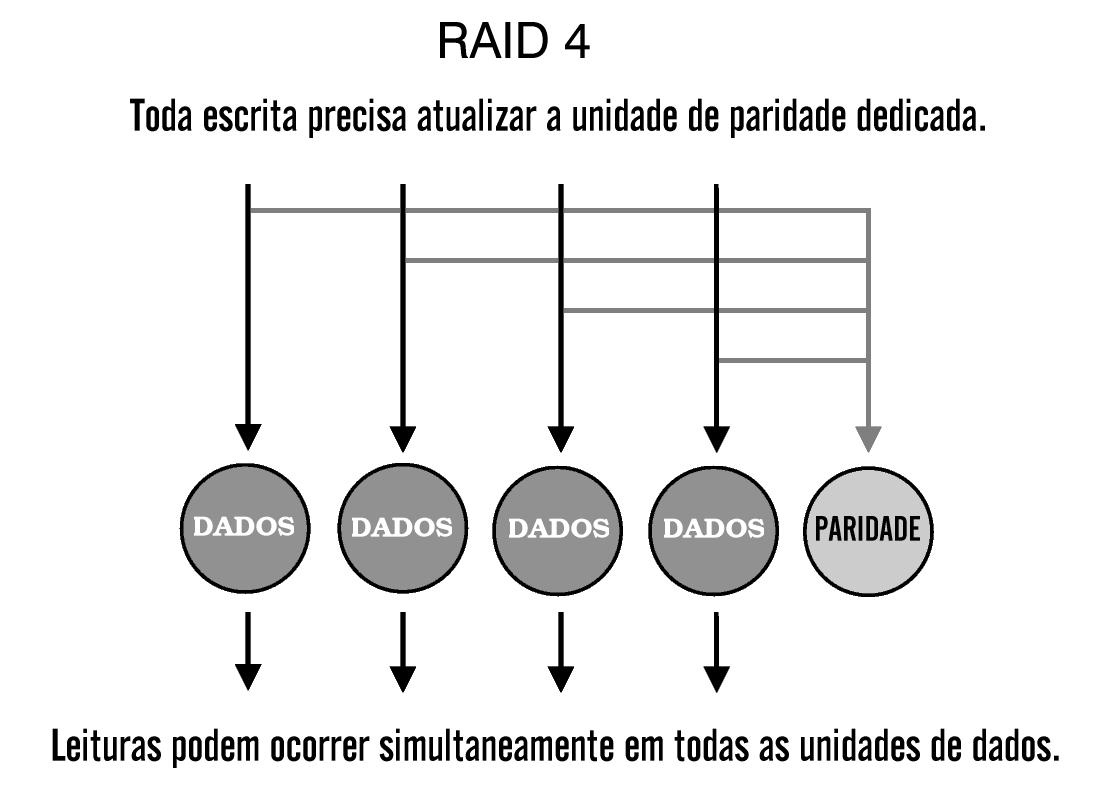
Sempre que os dados são escritos no arranjo, informações sobre paridade normalmente são lidas do disco de paridade e uma nova informação sobre paridade deve sempre ser escrita para o disco de paridade antes da próxima requisição de escrita ser realizada. Por causa dessas duas operações de E/S, o disco de paridade é o fator limitante do desempenho total do arranjo. Pelo fato do disco de paridade requerer somente um disco adicional para proteção de dados, arranjos RAID-4 são mais baratos que arranjos RAID-1.
RAID-5
Este tipo de RAID largamente usado funciona similarmente ao RAID 4, mas supera alguns dos problemas mais comuns sofridos por esse tipo. As informações sobre paridade para os dados do arranjo são distribuídas ao longo de todos os discos do arranjo, em vez de serem armazenadas em um disco dedicado.
Essa idéia de paridade distribuída reduz o gargalo de escrita (write bottleneck), que era o único disco de um RAID-4, porque agora as escritas concorrentes nem sempre requerem acesso às informações sobre paridade em um disco dedicado. Contudo, o desempenho de escrita geral ainda sofre por causa do processamento adicional causado pela leitura, re-cálculo e atualização da informação sobre paridade.
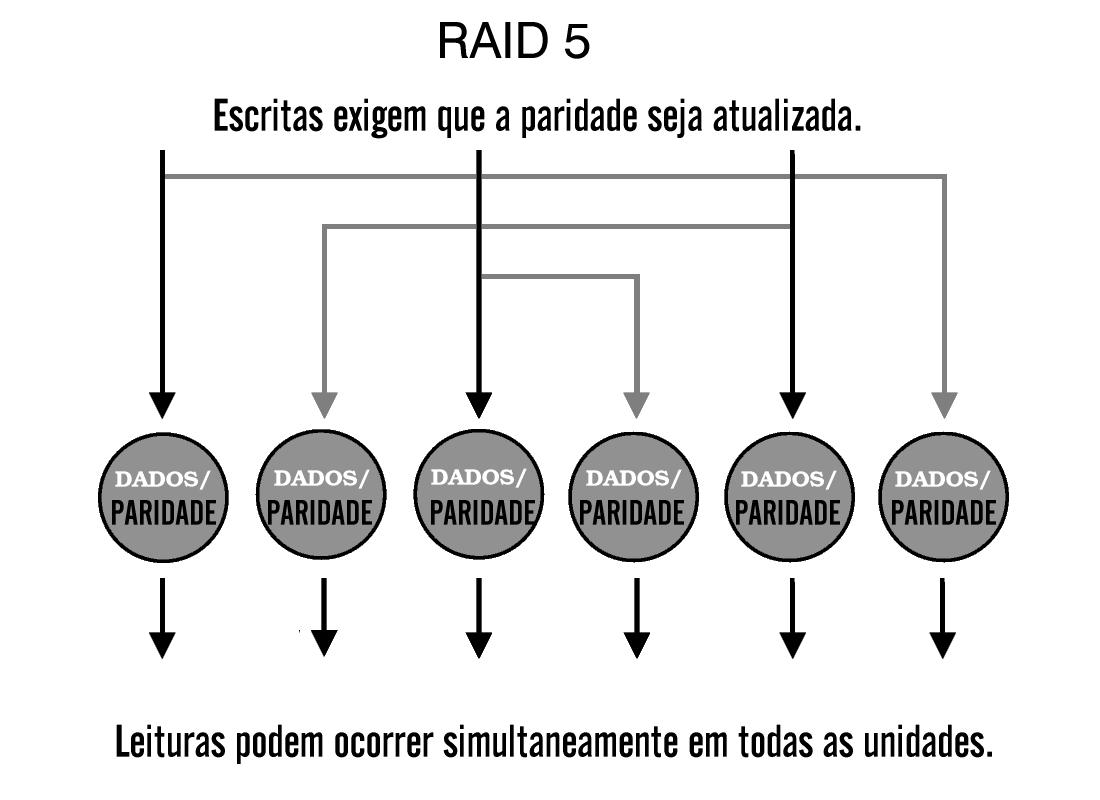
Para aumentar o desempenho de leitura de um arranjo RAID-5, o tamanho de cada segmento em que os dados são divididos pode ser otimizado para a aplicação que estiver usando o arranjo. O desempenho geral de um arranjo RAID-5 é equivalente ao de um RAID-4, exceto no caso de leituras seqüenciais, que reduzem a eficiência dos algoritmos de leitura por causa da distribuição das informações sobre paridade.
Como em outros arranjos baseados em paridade, a recuperação de dados em um arranjo RAID-5 é feita calculando a função XOR das informações dos discos restantes do arranjo. Pelo fato de a informação sobre paridade ser distribuída ao longo de todos os discos, a perda de qualquer disco reduz a disponibilidade de ambos os dados e da informação sobre paridade, até a recuperação do disco que falhou. Isto pode causar degradação do desempenho de leitura e de escrita.
Tipos Híbridos
Para suprir as deficiências de um nível ou outro de RAID é possível usar um nível de RAID sobre outro, aproveitando por exemplo, o excelente desempenho de um determinado nível e a confiabilidade de outro. Isso tudo, é claro, pagando o preço de uma maior quantidade de material.
Um exemplo é o RAID-10. Como o seu nome implica, é a combinação de discos espelhados (RAID-1) com a segmentação de dados (data stripping) (RAID-0).
O método de criação de um arranjo RAID-10 é diversificado. Em uma implementação RAID-0+1, os dados são segmentados através de grupos de discos espelhados, isto é, os dados são primeiro segmentados e para cada segmento é feito um espelho. Já em um RAID-1+0 os dados são primeiramente espelhados, e para cada espelho há a segmentação sobre vários discos.
RAID-10 oferece as vantagens da transferência de dados rápida de um arranjo espelhado, e as características de acessibilidade dos arranjos espelhados. O desempenho do sistema durante a reconstrução de um disco é também melhor que nos arranjos baseados em paridade, pois os dados são somente copiados do dispositivo sobrevivente.
O RAID-50 é um arranjo híbrido que usa as técnicas de RAID com paridade em conjunção com a segmentação de dados. Um arranjo RAID-50 é essencialmente um arranjo com as informações segmentadas através de dois ou mais arranjos RAID-5.
Dependendo do tamanho de cada segmento estabelecido durante a configuração do arranjo, estes arranjos híbridos podem oferecer os benefícios de acesso paralelo dos arranjos com paridade (alta velocidade na transferência de dados) ou de acesso independente dos arranjos com paridade (grande quantidade). Como em outros arranjos RAID com paridade, a reconstrução de um disco falho gera um impacto no desempenho do programa usando o arranjo.
Comparação dos Níveis de RAID
Pode-se fazer uma comparação entre os vários níveis de RAID, de acordo com desempenho (leitura, gravação e reconstrução), disponibilidade de dados e o número mínimo de unidades requeridas. Observe na tabela a descrição destes atributos para comparação dos níveis de RAID. Seguindo as referências:
-
A= Disponibilidade dos Dados
-
B= Desempenho de Leitura
-
C= Desempenho de Gravação
-
D= Desempenho de Reconstrução
-
E= Número Mínimo de Unidades Requeridas
Tabela 9-1. Atributos de Comparação dos Vários Níveis de RAID
|
Nível de RAID |
A |
B |
C |
D |
E |
|---|---|---|---|---|---|
|
RAID 0 |
Nenhuma |
Muito bom |
Muito bom |
Não disponível |
N |
|
RAID 1 |
Excelente |
Muito bom |
Bom |
Bom |
2N |
|
RAID 4 |
Boa |
E/S seqüencial: Boa E/S transacional: Boa |
E/S seqüencial: Muito boa E/S transacional: Ruim |
Satisfatória |
N + 1 (N pelo menos 2) |
|
RAID 5 |
Boa |
E/S seqüencial: Boa E/S transacional: Muito boa |
Satisfatória (a menos que o cache write-back seja usado) |
Ruim |
N + 1 (N pelo menos 2) |
|
RAID 10 |
Excelente |
Muito boa |
Satisfatória |
Boa |
2N |
|
RAID 50 |
Excelente |
Muito boa |
Satisfatória |
Satisfatória |
N+2 |
Nota: O número N é o requerimento de espaço para armazenamento de dados do nível de RAID. Exemplo: se o requisito mínimo é ter 6GB de espaço para um arranjo RAID-5, então deve-se ter ao menos 2 discos de 3GB cada e mais um disco de 3GB, sendo 6GB (dois discos) + 3GB (1 disco).
Implementação
Pré-requisitos
Para implementar a solução RAID, você precisa de:
-
Uma controladora de disco, caso o seu RAID seja via hardware;
-
É interessante utilizar um no-break para garantir a integridade do equipamento.
Instalação
Execute o Synaptic e instale os seguintes pacotes:
-
raidtools
-
util-linux
ou utilize o comando apt-get:
# apt-get install raidtools util-linux |
Configuração
Primeiramente, observe conteúdo do arquivo /proc/mdstat:
# cat /proc/mdstat |
Você sempre irá editar este arquivo para verificar as configurações de RAID. Observe que nenhum dispositivo de RAID está atualmente ativo.
Crie as partições que você desejar incluir em sua configuração de RAID; por exemplo:
# fdisk /dev/hda |
O próximo passo dependerá do nível de RAID que você escolheu usar; a seguir cada uma destas configurações serão vistas.
Modo Linear
Se você tem duas ou mais partições que não são necessariamente do mesmo tamanho, você poderá concatenar uma com a outra. Crie o arquivo /etc/raidtab para descrever sua configuração. Um arquivo raidtab em modo linear terá uma aparência semelhante a esta:
raiddev /dev/md0 |
Nos exemplos serão utilizadas duas partições de aproximadamente 1GB, sendo elas hda6 e hda7. Discos sobressalentes não são suportados aqui. Se um disco falhar, o arranjo irá falhar juntamente com ele. Não existem informações que possam ser colocadas em um disco sobressalente. Para criar o arranjo execute o comando:
# mkraid /dev/md0 |
Isto irá inicializar o arranjo, escrever os blocos persistentes e deixar pronto para uso. Verificando o arquivo /proc/mdstat você poderá ver que o arranjo está funcionando:
# cat /proc/mdstat |
Agora você já pode criar um sistema de arquivos, como se fosse em um dispositivo normal:
# mke2fs /dev/md0 |
Como está sendo usado o sistema de arquivos ext3 no exemplo, é interessante configurar o número de verificações que serão feitas no sistemas de arquivos do dispositivo:
# tune2fs -c 20 /dev/md0 |
Neste exemplo, a cada 20 inicializações será feita uma verificação. Em seguida, crie um ponto de montagem e montar o dispositivo:
# mkdir /mnt/md0 |
Observe que o tamanho total é de aproximadamente 2GB, pelo fato de ter sido feita uma concatenação de duas unidades, cada uma com aproximadamente 1GB.
RAID-0
Tendo dois ou mais dispositivos aproximadamente do mesmo tamanho, é possível combinar suas capacidades de armazenamento, bem como seus desempenhos, através do acesso em paralelo.
Modifique ou crie o arquivo /etc/raidtab para descrever a sua configuração. Observe o exemplo:
raiddev /dev/md0 |
Crie o dispositivo de RAID através dos comandos:
# raidstop /dev/md0 |
Isto irá inicializar os superblocos e iniciar o dispositivo RAID. Observando o arquivo /proc/mdstat pode-se ver:
# cat /proc/mdstat |
Agora o dispositivo /dev/md0 já está pronto. Pode ser criado um sistema de arquivos e ser montado para uso.
RAID-1
Com dois dispositivos aproximadamente do mesmo tamanho, é possível fazer com que um seja espelho do outro. Se você tiver mais dispositivos, poderá usá-los como um sistema de discos sobressalentes; isto será feito automaticamente por uma parte do espelho se um dos dispositivos operantes falhar.
Para isto, configure o arquivo /etc/raidtab da seguinte maneira:
raiddev /dev/md0 |
Nota: A configuração acima trata apenas de um exemplo. Você pode utilizar os dispositivos conforme a sua necessidade.
Se você usar discos sobressalentes, adicione no final da especificação do dispositivo o seguinte:
device /dev/hdb1 |
Onde /dev/hdb1 é um disco sobressalente. Configure o número de entrada dos discos sobressalentes, sempre de uma forma proporcional.
Tendo tudo pronto para começar a inicialização do RAID, o espelho poderá ser construído, e os índices (não no caso de dispositivos sem formatação) dos dois dispositivos serão sincronizados. Execute:
# mkraid /dev/md0 |
Neste momento veja este comando que irá fazer a inicialização do espelho. Observe agora o arquivo /proc/mdstat; ele irá mostrar que o dispositivo /dev/md0 foi inicializado, que o espelho começou a ser reconstruído, e quanto falta para a reconstrução ser completada:
# cat /proc/mdstat |
O processo de reconstrução é transparente: você poderá usar os dispositivos normalmente durante a execução deste processo. É possível até formatar o dispositivo enquanto a reconstrução está sendo executada. Você também pode montar e desmontar as unidades neste período (somente se um disco falhar esta ação será prejudicada).
Agora já é possível criar o sistema de arquivos, montar e visualizar o tamanho do dispositivo final:
# mount /dev/md0 /mnt/md0 |
Observe que o tamanho do dispositivo corresponde ao tamanho de um único dispositivo, por se tratar de um espelhamento de discos.
RAID-4
Com três ou mais dispositivos aproximadamente do mesmo tamanho, sendo um dispositivo significativamente mais rápido que os outros dispositivos, é possível combiná-los em um único dispositivo grande, mantendo ainda informação de redundância. Eventualmente você pode colocar alguns dispositivos para serem usados como discos sobressalentes.
Um exemplo de configuração para o arquivo /etc/raidtab:
raiddev /dev/md0 |
Se houver discos sobressalentes, será necessário configurar da mesma forma, seguindo as especificações do disco RAID. Veja o exemplo:
device /dev/hdb1 |
O disco sobressalente é criado de forma similar em todos os níveis de RAID. Inicialize o RAID-4 com o comando:
# mkraid /dev/md0 |
Você poderá acompanhar o andamento da construção do RAID através do arquivo /proc/mdstat:
# cat /proc/mdstat |
Para formatar o RAID-4, utilize as seguintes opções especiais do mke2fs:
# mke2fs -b 4096 -R stride=8 /dev/md0 |
Basta montar o RAID para uso. O tamanho total será de N-1, ou seja, o tamanho total de todos os dispositivos menos um, reservado para a paridade:
# df |
Note que o RAID-4 carrega o MD do RAID-5, porque são de níveis similares de RAID.
RAID-5
Similar ao RAID-4, porém é implementado através de três ou mais dispositivos de tamanho aproximado, combinados em um dispositivo maior. Ainda mantém um grau de redundância para proteger os dados. Podem ser usados discos sobressalentes, tomando parte de outros discos automaticamente, caso eles venham a falhar.
Se você está usando N dispositivos onde o menor tem um tamanho S, o tamanho total do arranjo será (N-1)*S. Esta perda de espaço é utilizada para a paridade (redundância) das informações. Assim, se algum disco falhar, todos os dados continuarão intactos. Porém, se dois discos falharem, todos os dados serão perdidos.
Configure o arquivo /etc/raidtab de uma forma similar a esta:
raiddev /dev/md0 |
Se existir algum disco sobressalente, ele pode ser inserido de uma maneira similar, seguindo as especificações de disco RAID. Por exemplo:
device /dev/hdb1 |
Um tamanho do pedaço (chunk size) de 32 KB é um bom padrão para sistemas de arquivos com uma finalidade genérica deste tamanho. O arranjo no qual o arquivo raidtab anterior é usado é de (n-1)*s = (3-1)*2 = 4 GB de dispositivo. Isto prevê um sistema de arquivos ext3 com um bloco de 4 KB de tamanho. Você poderia aumentar, juntamente com o arranjo, o tamanho do pedaço e o tamanho do bloco do sistema de arquivos.
Execute o comando mkraid para o dispositivo /dev/md0. Isto fará com que se inicie a reconstrução do seu arranjo. Observe o arquivo /proc/mdstat para poder fazer um acompanhamento do processo:
# cat /proc/mdstat |
Se o dispositivo for criado com sucesso, a reconstrução será iniciada. O arranjo não estará consistente até a fase de reconstrução ter sido completada. Entretanto, o arranjo é totalmente funcional (exceto para troca de dispositivos que falharam no processo); você pode formatar e usar o arranjo enquanto ele estiver sendo reconstruído.
Formate o arranjo com o comando:
# mke2fs -b 4096 -R stride=8 /dev/md0 |
Quando você tiver um dispositivo RAID executando, você pode sempre parar ou reiniciar usando os comandos: raidstop /dev/md0 ou raidstart /dev/md0.
Uso de RAID para Obter Alta Disponibilidade
Alta disponibilidade é difícil e cara. Quanto mais arduamente você tenta fazer um sistema ser tolerante a falhas, mais ele passa a ser dispendioso e difícil de implementar. As seguintes sugestões, dicas, idéias e suposições poderão ajudar você a respeito deste assunto:
-
Os discos IDE podem falhar de tal maneira que o disco que falhou em um cabo do IDE possa também impedir que um disco bom, no mesmo cabo, responda, dando a impressão de que os dois discos falharam. Apesar de RAID não oferecer proteção contra falhas em dois discos, você deve colocar apenas um disco em um cabo IDE, ou se houver dois discos, devem pertencer a configurações diferentes de RAID.
-
Observações similares são aplicadas às controladoras de disco. Não sobrecarregue os canais em uma controladora; utilize controladoras múltiplas.
-
Não utilize o mesmo tipo ou número de modelo para todos os discos. Não é incomum em variações elétricas bruscas perder dois ou mais discos, mesmo com o uso de supressores - eles não são perfeitos ainda. O calor e a ventilação insuficiente do compartimento de disco são outras causas das perdas de disco. Utilizar diferentes tipos de discos e controladoras diminui a probabilidade de danificação de um disco (calor, choque físico, vibração, choque elétrico).
-
Para proteger o disco contra falhas de controladora ou de CPU é possível construir um compartimento de disco SCSI que tenha cabos gêmeos, ou seja, conectado a dois computadores. Um computador irá montar o sistema de arquivos para leitura e escrita, enquanto outro computador irá montar o sistema de arquivos somente para leitura, e atuar como um computador reserva ativo. Quando o computador reserva é capaz de determinar que o computador mestre falhou (por exemplo, através de um adaptador watchdog), ele irá cortar a energia do computador mestre (para ter certeza de que ele está realmente desligado), e então fazer a verificação com o fsck e remontar o sistema para leitura e escrita.
-
Sempre utilize um no-break, e efetue os desligamentos corretamente. Embora um desligamento incorreto não possa danificar os discos, executar o ckraid mesmo em arranjos pequenos é extremamente lento. Você deve evitar a execução do ckraid sempre que for possível, ou pode colocar um hack no kernel e começar a reconstrução do código verificando erros.
-
Cabos SCSI são conhecidos por serem muito sujeitos a falhas, e podem causar todo tipo de problemas. Utilize o cabeamento de mais alta qualidade que você puder encontrar à venda. Utilize por exemplo o bubble-wrap para ter certeza de que os cabos não estão muito perto um do outro e do cross-talk. Observe rigorosamente as restrições do comprimento do cabo.
-
Dê uma olhada em SSI (arquitetura de armazenamento serial). Embora seja muito caro, parece ser menos vulnerável aos tipos de falhas que o SCSI apresenta.
Testando a Configuração
-
Simulando uma falha de drive: se você deseja fazer isto, basta "desligar o drive", ou seja, desligar a máquina. Se você está interessado em testar se seus dados podem resistir, faça realmente isto: desligue a máquina, retire o disco e reinicialize o sistema novamente. Lembre-se de que você não deve fazer isto em um sistema de produção: faça-o primeiro em uma máquina de testes.
Olhe os logs no syslog e no arquivo /proc/mdstat, para verificar como o RAID está indo. Lembre-se também de que você deve utilizar arranjos de RAID-{1,4,5} para ser capaz de sobreviver a falha de discos. RAID Linear ou RAID-0 irão falhar completamente quando o dispositivo for perdido.
-
Simulando Dados Corrompidos: RAID assume que se uma escrita para o disco não retorna erros, então a escrita foi feita com sucesso. Assim, se seu disco corrompe dados sem retornar erros, seus dados ficarão corrompidos. Isto é possível, mas difícil de acontecer, e poderia resultar em um sistema de arquivos corrompido.
Você pode corromper um sistema de arquivos (usando o comando dd, por exemplo). Porém, RAID não garante a integridade dos dados, ele apenas permite você manter seus dados se o disco "morre".